Microsoft SQL Server 2017 Datasheet ( 1 )

Microsoft SQL Server 2017 Datasheet ตอนที่ 1
รูปภาพ ข้างบน ผู้เขียนได้จาก เอกสาร SQL Server 2017 datasheet ซึ่งสามารถหาดาวน์โหลดได้จากลิ้งก์ต่อไปนี้ https://www.microsoft.com/en-us/sql-server/sql-server-2017

แพลตฟอร์มที่หลากหลาย
ปัจจุบัน Microsoft SQL Server 2017 สามารถติดตั้งได้บน หลายแพลตฟอร์ม ไม่ว่าจะเป็น Microsoft Windows เดิมหรือระบบปฏิบัติการ Linux ( มี Package ไม่ว่าจะมาจากตระกูล Redhat หรือ Debian อีกทั้งยังสามารถติดตั้งผ่าน Repositories ของแต่ละค่ายได้อีกด้วย)นอกเหนือจากนั้นยังสามารถห่อหุ้มด้วย Docker container แล้วนำไป Deploy บนแพลตฟอร์มอื่น รวมถึง Deploy ไปยัง Cloud Provider อาทิ OpenShift เป็นต้น

เป็นผู้นำด้านประสิทธิภาพ
Microsoft SQL Server 2017 นั้นพัฒนาต่อยอดจาก Microsoft SQL Server 2016 ซึ่ง ได้รับการจัด Position ใน Magic Quadrant ของ Gartner ให้เป็นผู้นำสูงสุดในกลุ่มผู้นำ ของอุตสาหกรรม Operational Database Management Systems 2 ปีซ้อน
ทั้งนี้ Gartner ได้ออกตัวว่า รายงานของ Gartner นั้นไม่ถือเป็นการรับรองผลิตภัณฑ์ ให้แก่เจ้าของผลิตภัณฑ์รายใด และไม่แนะนำให้เลือก ผลิตภัณฑ์เหล่านั้นตามคะแนนสูงสุดที่ได้ สิ่งพิมพ์ต่าง ๆ และผลวิจัยของ Gartner เป็นเพียงความเห็นของทาง Gartner เท่านั้น อาจไม่ใช่ข้อเท็จจริง และทาง Gartner ปฏิเสธการรับผิดชอบใด ๆ ที่เกิดจากการนำเอาผลวิจัยไปอ้างอิง
Microsoft SQL Server 2017 นั้นพัฒนาต่อยอดจาก Microsoft SQL Server 2016 ซึ่ง ได้รับการจัด Position ใน Magic Quadrant ของ Gartner ให้เป็นผู้นำสูงสุดในกลุ่มผู้นำ ของอุตสาหกรรม Operational Database Management Systems 2 ปีซ้อน
ทั้งนี้ Gartner ได้ออกตัวว่า รายงานของ Gartner นั้นไม่ถือเป็นการรับรองผลิตภัณฑ์ ให้แก่เจ้าของผลิตภัณฑ์รายใด และไม่แนะนำให้เลือก ผลิตภัณฑ์เหล่านั้นตามคะแนนสูงสุดที่ได้ สิ่งพิมพ์ต่าง ๆ และผลวิจัยของ Gartner เป็นเพียงความเห็นของทาง Gartner เท่านั้น อาจไม่ใช่ข้อเท็จจริง และทาง Gartner ปฏิเสธการรับผิดชอบใด ๆ ที่เกิดจากการนำเอาผลวิจัยไปอ้างอิง
นอกจากนั้น Microsoft SQL Server 2017 ยังได้รับการประเมินด้านประสิทธิภาพจาก Transaction Processing Council (TPC https://www.tpc.org )
ซึ่งมีหลายหมวดการทดสอบ ในที่นี้ขอพูดเพียงหมวด TPC-E ซึ่งเป็นการประเมินสำหรับฐานข้อมูล แบบ OLTP (Online Transaction Processing) สมัยใหม่ และ TPC-H ซึ่งเป็นการประเมินสำหรับฐานข้อมูลแบบ OLAP (Online Analytical Processing ) เท่านั้น
TPC เป็นองค์กรไม่แสวงหากำไร จัดตั้งขึ้นเพื่อ สร้างเกณฑ์ในการทดสอบ โดยดูจากประสิทธิภาพในการประมวลผล Transaction ของระบบจัดการฐานข้อมูล และเผยแพร่ผลการทดสอบนั้นอย่างเป็นกลาง มีสมาชิกส่วนใหญ่เป็นบริษัทที่มีผลิตภัณฑ์ด้านฐานข้อมูล และเครื่องเซิร์ฟเวอร์ที่ให้บริการฐานข้อมูล โดยส่งผลิตภัณฑ์ของตนเข้าทดสอบอย่างสม่ำเสมอ อาทิ Microsoft, Oracle, IBM, SAP, TERADATA, Fujitsu, Hitachi, Lenovo และ Hewlett Packard เป็นต้น
ซึ่งมีหลายหมวดการทดสอบ ในที่นี้ขอพูดเพียงหมวด TPC-E ซึ่งเป็นการประเมินสำหรับฐานข้อมูล แบบ OLTP (Online Transaction Processing) สมัยใหม่ และ TPC-H ซึ่งเป็นการประเมินสำหรับฐานข้อมูลแบบ OLAP (Online Analytical Processing ) เท่านั้น
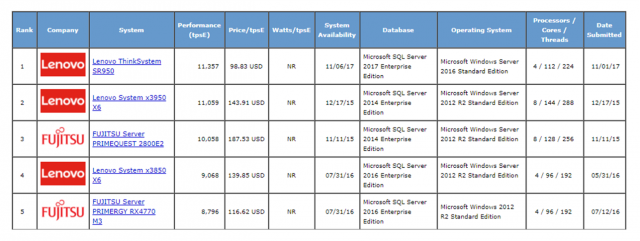
- TPC-E พบว่า Microsoft SQL Server 2017 Enterprise Edition บนระบบปฏิบัติการ Microsoft Windows 2016 Standard Edition โดยใช้ CPU 4 Sockets มีจำนวน 112 Cores ให้ประสิทธิภาพสูงที่สุด
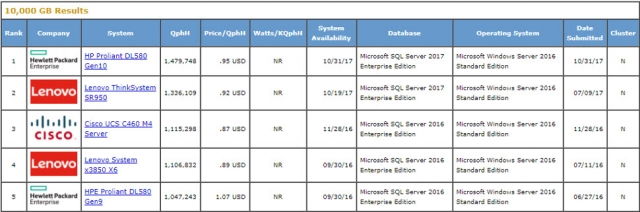
- TPC-H พบว่า Microsoft SQL Server Enterprise Edition บนระบบปฏิบัติการ SUSE Linux Enterprise Server 12 ให้ประสิทธิภาพสูงสุด สำหรับขนาดข้อมูล 1,000 กิกะไบต์
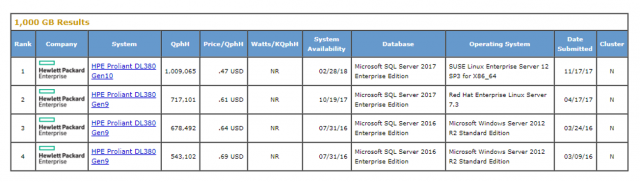
และ Microsoft SQL Server 2017 Enterprise Edition บนระบบปฏิบัติการ Microsoft Windows Server 2016 Standard Edition ให้ประสิทธิภาพสูงสุด สำหรับขนาดฐานข้อมูล 10,000 กิกะไบต์
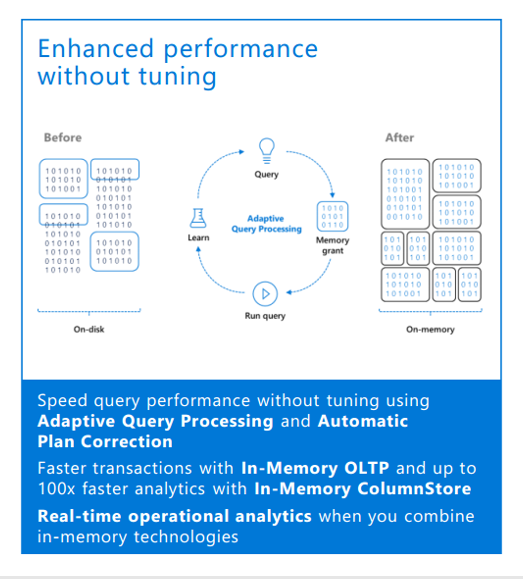
เพิ่มประสิทธิภาพโดยไม่ต้องปรับแต่งใด ๆ
Microsoft SQL Server 2017 ได้เพิ่มความเร็วให้กับการ Query โดยไม่ต้องทำการปรับแต่งใด ๆ ผ่านทาง Adaptive Query processing และ Automatic Plan Correction
โดย Adaptive Query processing ประกอบด้วย
- Interleaved Execution
- Batch mode adaptive join
- Batch mode memory grant feedback
Interleaved Execution
Cardinality Estimation เป็นส่วนหนึ่งของ Query Optimizer เพื่อคาดคะเนจำนวนแถวข้อมูล (Estimated Number of Rows) ที่จะถูกดำเนินการในแต่ละตัวดำเนินการภายใน Planโดยอาศัยข้อมูล Histogram และ Density Vector จาก Statistics มาคำนวน
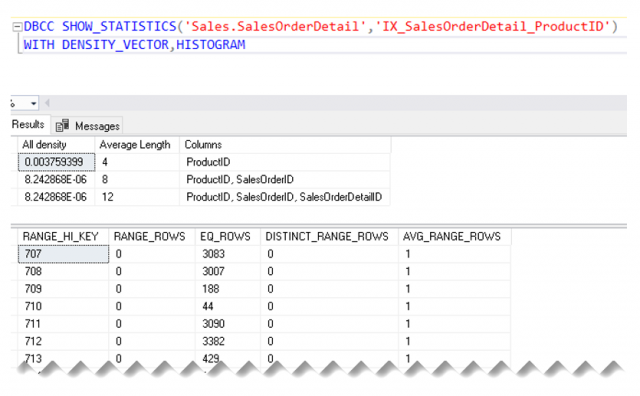
หากคาดคะเนจำนวนแถวข้อมูล (Estimated Number of Rows) คาดเคลื่อน (Inaccurate) ไปจากจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) จะส่งผลกระทบถึง
สำหรับ Interleaved Execution ยังอยู่ในช่วงเริ่มต้น สามารถแก้ไขการคาดคะเนจำนวนแถวข้อมูล (Estimated Number of Rows) บนตัวดำเนินการของ Multi-Statement Table Valued Functions ได้เท่านั้น แต่จะมีการปรับปรุงให้ใช้กับตัวดำเนินการอื่นในลำดับต่อไป
ก่อนอื่นผู้เขียนได้ทดลองเขียน Multi-Statement Table Valued Functions ขึ้นมา
โดยใช้ฐานข้อมูล Adventureworks2016 เป็นฐานข้อมูลตัวอย่าง บน Microsoft SQL Server 2017 ดังนี้
ก่อนหน้าที่จะมี Interleaved Execution กลไก Cardinality Estimation
จะไม่สามารถคาดคะเนจำนวนแถวข้อมูลบนตัวดำเนินการของ Multi-Statement Table Valued Functions ได้
ทำได้เพียงกำหนดเป็นค่าตายตัวดังนี้
โดยมีการเรียกใช้ Multi-Statement Table Valued Function ที่สร้างขึ้นก่อนหน้าร่วมด้วย
ให้เลือก Include Actual Execution Plan ก่อนทำการ Execute สคริปต์ข้างบน
จะได้ Actual Execution Plan ดังนี้
- ลำดับการ Join
- ลำดับการ Join ผิดพลาด ตารางที่ควรอยู่ซ้ายไปอยู่ขวาให้ผลประสิทธิภาพแย่ลง
- เลือกตัวดำเนินการ Join (Merge/Hash/Nest Loop) ผิดพลาด
- Plan ที่ถูกเลือกอาจไม่ดี และ Plan ที่ดีอาจไม่ถูกเลือก
- เพื่อเลือกตัวดำเนินการผิด ๆ มาสร้าง Plan
- การประมวลผล Plan ไร้ประสิทธิภาพ
- จองหน่วยความจำคาดเคลื่อน
- จองมากไป เปลืองหน่วยความจำ และทำให้การใช้งานพร้อมกัน (Concurrency) น้อยลง เกิดแถวคอยมากขึ้น
- จองน้อยไป ต้องอาศัยพื้นที่บนดิสก์ช่วย
- เปลืองการทำงานของ CPU และ I/O มาดำเนินการตรวจสอบแถวที่ไม่ใช้ทิ้งไป
- จองหน่วยความจำคาดเคลื่อน
- 1st Generation ถูกพัฒนาและใช้มาตั้งแต่มี Microsoft SQL Server มา จนถึง Microsoft SQL Server 2012 โดย Microsoft เรียก Generation นี้ว่า Legacy Cardinality Estimation
- 2nd Generation ถูกพัฒนาและใช้ตั้งแต่ Microsoft SQL Server 2014 เป็นต้นไป
สำหรับ Interleaved Execution ยังอยู่ในช่วงเริ่มต้น สามารถแก้ไขการคาดคะเนจำนวนแถวข้อมูล (Estimated Number of Rows) บนตัวดำเนินการของ Multi-Statement Table Valued Functions ได้เท่านั้น แต่จะมีการปรับปรุงให้ใช้กับตัวดำเนินการอื่นในลำดับต่อไป
/*---------------------------------------------------------------- CREATE Multi-Statement Table Valued Functions Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ CREATE OR ALTER FUNCTION Sales.GetOrdersbyTerritoryID(@TerritoryID int) RETURNS @Result TABLE ( SalesOrderID int , OrderDate datetime , TotalDue decimal(20,4) , CustomerName varchar(200) ) AS BEGIN INSERT INTO @Result SELECT O.SalesOrderID , O.OrderDate , O.TotalDue , P.FirstName+' '+P.LastName as CustomerName FROM Sales.SalesOrderHeader as O INNER JOIN Sales.Customer as C ON O.CustomerID=C.CustomerID INNER JOIN Person.Person as P ON P.BusinessEntityID=C.PersonID WHERE O.TerritoryID=@TerritoryID; RETURN END;
ก่อนอื่นผู้เขียนได้ทดลองเขียน Multi-Statement Table Valued Functions ขึ้นมา
โดยใช้ฐานข้อมูล Adventureworks2016 เป็นฐานข้อมูลตัวอย่าง บน Microsoft SQL Server 2017 ดังนี้
ก่อนหน้าที่จะมี Interleaved Execution กลไก Cardinality Estimation
จะไม่สามารถคาดคะเนจำนวนแถวข้อมูลบนตัวดำเนินการของ Multi-Statement Table Valued Functions ได้
ทำได้เพียงกำหนดเป็นค่าตายตัวดังนี้
- กรณี 1st Generation จะคาดคะเนจำนวนแถวข้อมูลมีค่าเป็น 1 เป็นค่าตายตัว
- กรณี 2nd Generation จะคาดคะเนจำนวนแถวข้อมูลมีค่าเป็น 100 เป็นค่าตายตัว
โดยมีการเรียกใช้ Multi-Statement Table Valued Function ที่สร้างขึ้นก่อนหน้าร่วมด้วย
/*---------------------------------------------------------------- Test ON Legacy Cardinality Estimation Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ ALTER DATABASE Adventureworks SET COMPATIBILITY_LEVEL = 110; --SQL Server 2012 GO --สามารถใช้คำสั่งข้างล่างแทนการเปลี่ยน Compatibility Level ได้ --ALTER DATABASE SCOPED CONFIGURATION SET LEGACY_CARDINALITY_ESTIMATION = ON ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO SELECT * FROM Sales.GetOrdersbyTerritoryID(9) as O INNER JOIN Sales.SalesOrderDetail as OD ON O.SalesOrderID=OD.SalesOrderID GO
ให้เลือก Include Actual Execution Plan ก่อนทำการ Execute สคริปต์ข้างบน
จะได้ Actual Execution Plan ดังนี้
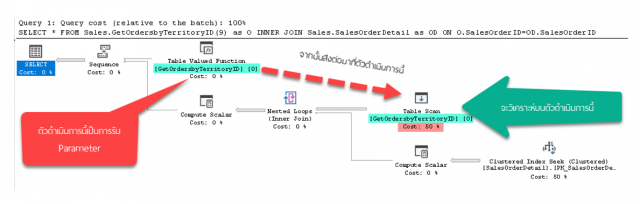
เราจะวิเคราะห์บนตัวดำเนินการ Table Scan ซึ่งเกิดจาก Multi-Statement Table Valued Function ชื่อ GetOrdersbyTerritoryID
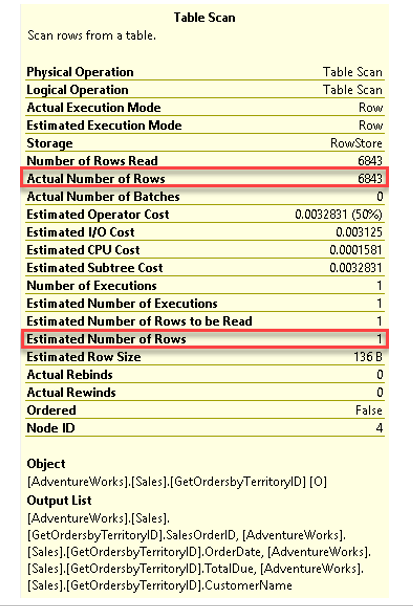
พบว่าจำนวนแถวข้อมูลที่คาดคะเน (Estimated Number of Rows) มีค่าเท่ากับ 1 ซึ่งเป็นค่าตายตัว
มีความคาดเคลื่อนไปจากจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวนถึง 6,843 แถวข้อมูล
ผู้เขียนจะทำการทดสอบอีกครั้ง โดยเปลี่ยน Database Compatibility Level เป็น 130 (Microsoft SQL Server 2016)
ซึ่งใช้ Cardinality Estimation แบบ 2nd Generation จากนั้นทำการ Query
โดยมีการเรียกใช้ Multi-Statement Table Valued Function ที่สร้างขึ้นก่อนหน้าร่วมด้วย
(แนะนำให้ขึ้น Session ใหม่เพื่อผลทดลองไม่คาดเคลื่อน)
ให้เลือก Include Actual Execution Plan ก่อนทำการ Execute สคริปต์ข้างบน
จะได้ Actual Execution Plan ดังนี้
มีความคาดเคลื่อนไปจากจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวนถึง 6,843 แถวข้อมูล
ผู้เขียนจะทำการทดสอบอีกครั้ง โดยเปลี่ยน Database Compatibility Level เป็น 130 (Microsoft SQL Server 2016)
ซึ่งใช้ Cardinality Estimation แบบ 2nd Generation จากนั้นทำการ Query
โดยมีการเรียกใช้ Multi-Statement Table Valued Function ที่สร้างขึ้นก่อนหน้าร่วมด้วย
(แนะนำให้ขึ้น Session ใหม่เพื่อผลทดลองไม่คาดเคลื่อน)
/*---------------------------------------------------------------- Test ON Current Cardinality Estimation Script By: 9Expet Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ ALTER DATABASE Adventureworks SET COMPATIBILITY_LEVEL = 130; --SQL Server 2016 GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO SELECT * FROM Sales.GetOrdersbyTerritoryID(9) as O INNER JOIN Sales.SalesOrderDetail as OD ON O.SalesOrderID=OD.SalesOrderID GO
ให้เลือก Include Actual Execution Plan ก่อนทำการ Execute สคริปต์ข้างบน
จะได้ Actual Execution Plan ดังนี้
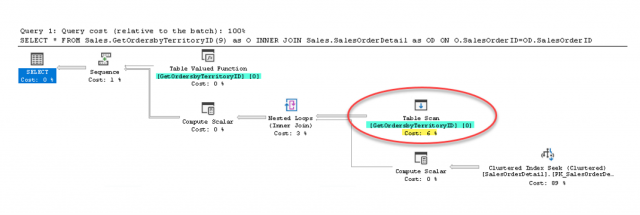
เราจะวิเคราะห์บนตัวดำเนินการ Table Scan ซึ่งเกิดจาก Multi-Statement Table Valued Function ชื่อ GetOrdersbyTerritoryID

พบว่า Cost ในการดำเนินการบนตัวดำเนินการนี้ลดลงจาก 50% เหลือเพียง 6%
และจำนวนแถวข้อมูลที่คาดคะเน (Estimated Number of Rows) มีค่าเท่ากับ 100 ซึ่งเป็นค่าตายตัว
มีความคาดเคลื่อนไปจากจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวนถึง 6,843 แถวข้อมูล
ซึ่งก็ถือว่ามีความคาดเคลื่อนมากอยู่ดี
ผู้เขียนจะทำการทดสอบครั้งสุดท้าย โดยเปลี่ยน Database Compatibility Level เป็น 140 (Microsoft SQL Server 2017) ซึ่งเพิ่มเติม Interleaved Execution ลงไป จากนั้นทำการ Query
โดยมีการเรียกใช้ Multi-Statement Table Valued Function ที่สร้างขึ้นก่อนหน้าร่วมด้วย
(แนะนำให้ขึ้น Session ใหม่เพื่อผลทดลองไม่คาดเคลื่อน)
ให้เลือก Include Actual Execution Plan ก่อนทำการ Execute สคริปต์ข้างบน
จะได้ Actual Execution Plan ดังนี้
และจำนวนแถวข้อมูลที่คาดคะเน (Estimated Number of Rows) มีค่าเท่ากับ 100 ซึ่งเป็นค่าตายตัว
มีความคาดเคลื่อนไปจากจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวนถึง 6,843 แถวข้อมูล
ซึ่งก็ถือว่ามีความคาดเคลื่อนมากอยู่ดี
ผู้เขียนจะทำการทดสอบครั้งสุดท้าย โดยเปลี่ยน Database Compatibility Level เป็น 140 (Microsoft SQL Server 2017) ซึ่งเพิ่มเติม Interleaved Execution ลงไป จากนั้นทำการ Query
โดยมีการเรียกใช้ Multi-Statement Table Valued Function ที่สร้างขึ้นก่อนหน้าร่วมด้วย
(แนะนำให้ขึ้น Session ใหม่เพื่อผลทดลองไม่คาดเคลื่อน)
/*---------------------------------------------------------------- Test ON Current Cardinality Estimation+ Interleaved Execution Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ ALTER DATABASE Adventureworks SET COMPATIBILITY_LEVEL = 140; --SQL Server 2017 GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO SELECT * FROM Sales.GetOrdersbyTerritoryID(9) as O INNER JOIN Sales.SalesOrderDetail as OD ON O.SalesOrderID=OD.SalesOrderID GO
ให้เลือก Include Actual Execution Plan ก่อนทำการ Execute สคริปต์ข้างบน
จะได้ Actual Execution Plan ดังนี้
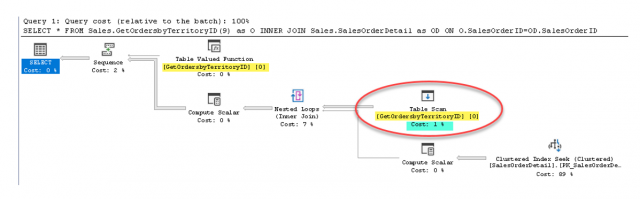
เราจะวิเคราะห์บนตัวดำเนินการ Table Scan ซึ่งเกิดจาก Multi-Statement Table Valued Function ชื่อ GetOrdersbyTerritoryID

พบว่า Cost ในการดำเนินการบนตัวดำเนินการนี้ลดลง เหลือ 1%
และจำนวนแถวข้อมูลที่คาดคะเน (Estimated Number of Rows) มีค่าเท่ากับ 6,843 ซึ่งตรงกันกับจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวน 6,843 แถวข้อมูลเท่ากัน
เป็นเพราะกลไก Interleaved Execution นี้ เมื่อพบ Multi-Statement Table Valued Function อยู่ร่วมใน Query ก็จะกระโดดออกไปดำเนินการในส่วนของ Multi-Statement Table Valued Function ก่อน เพื่อให้ได้จำนวนแถวข้อมูลที่แน่ชัด (เกิดจากการ Execute จริงเพื่อให้ได้ Actual Plan ของ Multi-Statement Table Valued Function และนำจำนวนแถวข้อมูลที่เป็นผลลัพธ์มาใช้) มาใช้คาดคะเนจำนวนแถวข้อมูลร่วมกับ Plan ของ Query ต่อไป
เมื่อ Cardinality Estimation หรือการคาดคะเนจำนวนแถวข้อมูลสำหรับ Multi-Statement Table Valued Function ถูกต้อง Plan รวมของ Query ก็จะมีประสิทธิภาพ
แต่ทั้งนี้ขึ้นอยู่กับ Cardinality Estimation ในตัวดำเนินการอื่น ๆ ที่อยู่ใน Plan จะต้องคาดเคลื่อนน้อยด้วย
แต่ก็มีข้อยกเว้นสำหรับ Interleaved Execution อยู่เหมือนกัน คือยังไม่สามารถทำงานได้
หาก Multi-Statement Table Valued Function ถูกใช้ผ่านประโยค CROSS APPLY ดังนี้
จะได้ Actual Plan ออกมาแบบนี้
และจำนวนแถวข้อมูลที่คาดคะเน (Estimated Number of Rows) มีค่าเท่ากับ 6,843 ซึ่งตรงกันกับจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวน 6,843 แถวข้อมูลเท่ากัน
เป็นเพราะกลไก Interleaved Execution นี้ เมื่อพบ Multi-Statement Table Valued Function อยู่ร่วมใน Query ก็จะกระโดดออกไปดำเนินการในส่วนของ Multi-Statement Table Valued Function ก่อน เพื่อให้ได้จำนวนแถวข้อมูลที่แน่ชัด (เกิดจากการ Execute จริงเพื่อให้ได้ Actual Plan ของ Multi-Statement Table Valued Function และนำจำนวนแถวข้อมูลที่เป็นผลลัพธ์มาใช้) มาใช้คาดคะเนจำนวนแถวข้อมูลร่วมกับ Plan ของ Query ต่อไป
เมื่อ Cardinality Estimation หรือการคาดคะเนจำนวนแถวข้อมูลสำหรับ Multi-Statement Table Valued Function ถูกต้อง Plan รวมของ Query ก็จะมีประสิทธิภาพ
แต่ทั้งนี้ขึ้นอยู่กับ Cardinality Estimation ในตัวดำเนินการอื่น ๆ ที่อยู่ใน Plan จะต้องคาดเคลื่อนน้อยด้วย
แต่ก็มีข้อยกเว้นสำหรับ Interleaved Execution อยู่เหมือนกัน คือยังไม่สามารถทำงานได้
หาก Multi-Statement Table Valued Function ถูกใช้ผ่านประโยค CROSS APPLY ดังนี้
/*---------------------------------------------------------------- CROSS APPLY ON Current Cardinality Estimation + Interleaved Execution Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ ALTER DATABASE Adventureworks SET COMPATIBILITY_LEVEL = 140; --SQL Server 2017 GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO SELECT * FROM Sales.SalesTerritory as T CROSS APPLY Sales.GetOrdersbyTerritoryID(T.TerritoryID) as O;
จะได้ Actual Plan ออกมาแบบนี้
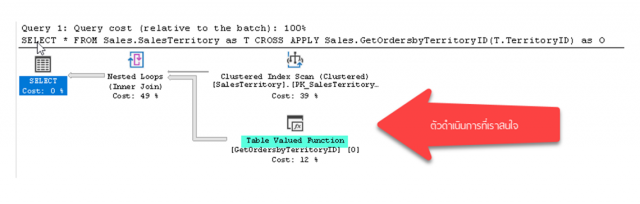
เราจะวิเคราะห์บนตัวดำเนินการ Table Valued Function ซึ่งเกิดจาก Multi-Statement Table Valued Function ชื่อ GetOrdersbyTerritoryID ตัวเดียวกับที่เราทดสอบมาตลอด

พบว่าจำนวนแถวข้อมูลที่คาดคะเน (Estimated Number of Rows) มีค่าเท่ากับ 100 ซึ่งเป็นค่าตายตัว
มีความคาดเคลื่อนไปจากจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวนถึง 31,465 แถวข้อมูล
กลับไปคาดเคลื่อนอีกครั้งทั้งที่ Database Compatibility Level เป็น Microsoft SQL Server 2017 และมี Multi-Statement Table Valued Function อยู่ใน Query แต่ Interleaved Execution จะไม่ทำงานหาก Multi-Statement Table Valued Function ถูกเรียกใช้โดยประโยค CROSS APPLY
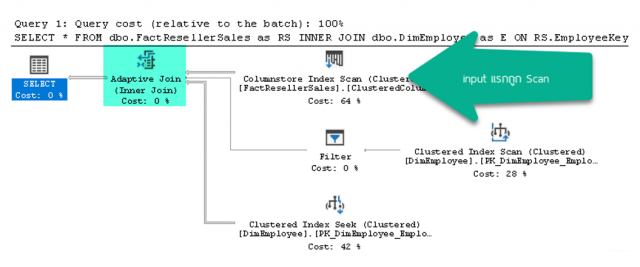
เป็นการยืดการเลือกตัวดำเนินการ Physical Join ว่าจะเป็น Hash Match หรือ Nested Loop ออกไปหลังจากทำการสะแกน input แรก หลังจากนั้นนำมาเทียบกับค่าเกณฑ์วัดที่คำนวณได้
หากต่ำกว่าเกณฑ์วัด จะเลือกเป็น Nested Loop
แต่หากมากกว่าหรือเท่ากับก็จะดำเนินโดย Hash Match
ผู้เขียนทดลองด้วยฐานข้อมูล AdventureworksDW2016 ซึ่งเป็นฐานข้อมูลแบบ Data Warehouse บนระบบจัดการฐานข้อมูล Microsoft SQL Server 2017 ด้วยสคริปต์ต่อไปนี้
จะได้ Actual Plan มีตัวดำเนินการ Adaptive Join ต้องแสดงรายละเอียดของตัวดำเนินการออกมา
ถึงจะทราบว่าเลือกใช้ Hash Match หรือ Nested Loop กันแน่
มีความคาดเคลื่อนไปจากจำนวนแถวข้อมูลที่ได้รับจริง (Actual Number of Rows) ซึ่งมีจำนวนถึง 31,465 แถวข้อมูล
กลับไปคาดเคลื่อนอีกครั้งทั้งที่ Database Compatibility Level เป็น Microsoft SQL Server 2017 และมี Multi-Statement Table Valued Function อยู่ใน Query แต่ Interleaved Execution จะไม่ทำงานหาก Multi-Statement Table Valued Function ถูกเรียกใช้โดยประโยค CROSS APPLY
Batch Mode Adaptive Join
เป็นการยืดการเลือกตัวดำเนินการ Physical Join ว่าจะเป็น Hash Match หรือ Nested Loop ออกไปหลังจากทำการสะแกน input แรก หลังจากนั้นนำมาเทียบกับค่าเกณฑ์วัดที่คำนวณได้หากต่ำกว่าเกณฑ์วัด จะเลือกเป็น Nested Loop
แต่หากมากกว่าหรือเท่ากับก็จะดำเนินโดย Hash Match
ผู้เขียนทดลองด้วยฐานข้อมูล AdventureworksDW2016 ซึ่งเป็นฐานข้อมูลแบบ Data Warehouse บนระบบจัดการฐานข้อมูล Microsoft SQL Server 2017 ด้วยสคริปต์ต่อไปนี้
/*---------------------------------------------------------------- Test Adaptive Join #1 Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ ALTER DATABASE AdventureworksDW SET COMPATIBILITY_LEVEL = 140; --2017 GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO SELECT * FROM dbo.FactResellerSales as RS INNER JOIN dbo.DimEmployee as E ON RS.EmployeeKey=E.EmployeeKey WHERE RS.SalesAmount>15000;
จะได้ Actual Plan มีตัวดำเนินการ Adaptive Join ต้องแสดงรายละเอียดของตัวดำเนินการออกมา
ถึงจะทราบว่าเลือกใช้ Hash Match หรือ Nested Loop กันแน่
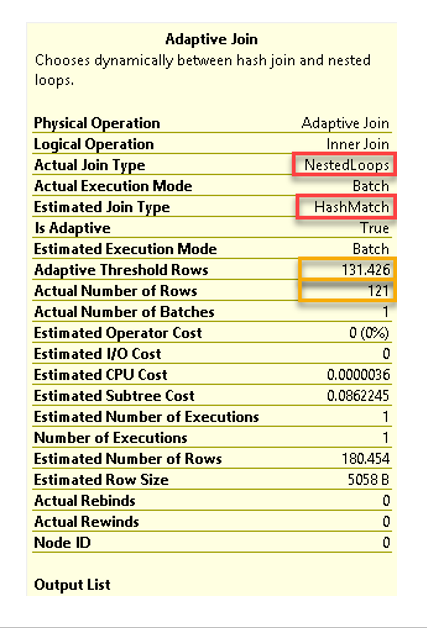
พบว่ามีการคาดคะเนชนิดของ Physical Join เอาไว้เป็น Hash Match
แต่ได้เปลี่ยนไปใช้ Nested Loops แทน
เพราะมีการคำนวณค่า Adaptive Threshold Rows หรือเกณฑ์ตัดสินออกมาได้เท่ากับ 131.426 แถว
แต่แถวข้อมูลที่สะแกนได้จริงจาก input แรก (Columnstore Index Scan) ได้เท่ากับ 121 แถว
ซึ่งต่ำกว่าเกณฑ์ตัดสิน จึงเปลี่ยนไปใช้ Nested Loops แทน
ผู้เขียนทำการทดลองครั้งที่สอง
โดยเพิ่มจำนวนแถวข้อมูลที่ได้จากการสะแกน input แรก ดังสคริปต์ต่อไปนี้
หน้าตาของ Actual Plan ที่ได้ไม่ต่างจากเดิมมีเปอร์เซ็นในบางตัวดำเนินเปลี่ยนแปลงไปบ้าง
ผู้เขียนขอเอาเฉพาะรายละเอียดของตัวดำเนินการ Adaptive Join มาแสดงดังนี้
แต่ได้เปลี่ยนไปใช้ Nested Loops แทน
เพราะมีการคำนวณค่า Adaptive Threshold Rows หรือเกณฑ์ตัดสินออกมาได้เท่ากับ 131.426 แถว
แต่แถวข้อมูลที่สะแกนได้จริงจาก input แรก (Columnstore Index Scan) ได้เท่ากับ 121 แถว
ซึ่งต่ำกว่าเกณฑ์ตัดสิน จึงเปลี่ยนไปใช้ Nested Loops แทน
ผู้เขียนทำการทดลองครั้งที่สอง
โดยเพิ่มจำนวนแถวข้อมูลที่ได้จากการสะแกน input แรก ดังสคริปต์ต่อไปนี้
/*---------------------------------------------------------------- Test Adaptive Join #2 Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ ALTER DATABASE AdventureworksDW SET COMPATIBILITY_LEVEL = 140; --2017 GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO SELECT * FROM dbo.FactResellerSales as RS INNER JOIN dbo.DimEmployee as E ON RS.EmployeeKey=E.EmployeeKey WHERE RS.SalesAmount>12000;
หน้าตาของ Actual Plan ที่ได้ไม่ต่างจากเดิมมีเปอร์เซ็นในบางตัวดำเนินเปลี่ยนแปลงไปบ้าง
ผู้เขียนขอเอาเฉพาะรายละเอียดของตัวดำเนินการ Adaptive Join มาแสดงดังนี้
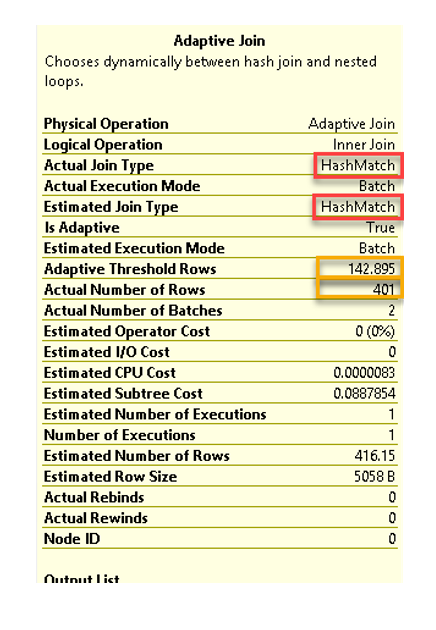
พบว่ามีการคาดคะเนชนิดของ Physical Join เอาไว้เป็น Hash Match และใช้จริงก็เป็น Hash Match
เพราะมีการคำนวณค่า Adaptive Threshold Rows หรือเกณฑ์ตัดสินออกมาได้เท่ากับ 142.895 แถว
แต่แถวข้อมูลที่สะแกนได้จริงจาก input แรก (Columnstore Index Scan) ได้เท่ากับ 401 แถว
ซึ่งสูงกว่าเกณฑ์ตัดสิน จึงยังคงใช้ Hash Match ต่อไป
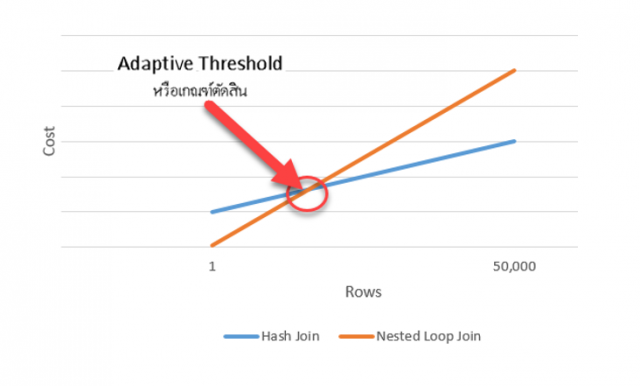
เพราะตัวดำเนินการ Nested Loops นั้นจะเสีย Cost น้อยกว่า
หากจำนวนแถวข้อมูลไม่เกินเกณฑ์ตัดสิน ที่คำนวณได้
แต่หากจำนวนแถวข้อมูลเกินเกณฑ์ตัดสิน จะเสีย Cost มากกว่า Hash Match ดังรูป
เพราะมีการคำนวณค่า Adaptive Threshold Rows หรือเกณฑ์ตัดสินออกมาได้เท่ากับ 142.895 แถว
แต่แถวข้อมูลที่สะแกนได้จริงจาก input แรก (Columnstore Index Scan) ได้เท่ากับ 401 แถว
ซึ่งสูงกว่าเกณฑ์ตัดสิน จึงยังคงใช้ Hash Match ต่อไป
เพราะตัวดำเนินการ Nested Loops นั้นจะเสีย Cost น้อยกว่า
หากจำนวนแถวข้อมูลไม่เกินเกณฑ์ตัดสิน ที่คำนวณได้
แต่หากจำนวนแถวข้อมูลเกินเกณฑ์ตัดสิน จะเสีย Cost มากกว่า Hash Match ดังรูป
Batch Mode Memory Grant Feedback
หน่วยความจำถูกใช้งานเพื่อจัดเก็บแถวข้อมูลที่เกิดจากตัวดำเนินการ Hash Match และ Sortโดยขนาดความจุของหน่วยความจำได้มาจากกลไก Cardinality Estimation
และบันทึกขนาดความจุดังกล่าวไว้กับ Plan ที่ถูกคอมไพล์ (Cached Plan)
หากกลไก Cardinality Estimation คลาดเคลื่อนจะส่งผลเสียตามมา
เนื่องจากจัดสรรขนาดความจุของหน่วยความจำมากหรือน้อยเกินไป
- หากการคาดคะเนต่ำกว่าความเป็นจริง ทำให้การจัดสรรขนาดความจุของหน่วยความจำมีขนาดเล็กเกินไป ไม่เพียงพอ ทำให้แถวข้อมูลที่เกินรั่วไหลลงสู่ดิสก์ (Spill to Disk) ซึ่งทำให้ประสิทธิภาพแย่กว่าการที่ทั้งหมดอยู่ในหน่วยความจำ
- หากคาดคะเนสูงเกินกว่าความเป็นจริงไปมาก ทำให้การจัดสรรขนาดความจุของหน่วยความจำมีขนาดใหญ่เกินไป ก็เกิดผลเสียกับภาวะการใช้งานพร้อมกัน (Concurrency) เพราะ Query จะเกิดการรอคอย (Waits) ในแถวคอย จนกว่าจะมีหน่วยความจำเพียงพอกับที่ต้องการ
ก็จะเกิดการคำนวณขนาดความจุของหน่วยความจำที่ต้องใช้ใหม่และปรับปรุงลงใน Cached Plan
ก่อนอื่นผู้เขียนจะทำการเลือกตารางที่มีจำนวนแถวข้อมูลพอเหมาะจากฐานข้อมูล AdventureworksDW มาใช้งาน
โดยสามารถหาได้จาก Standard Report
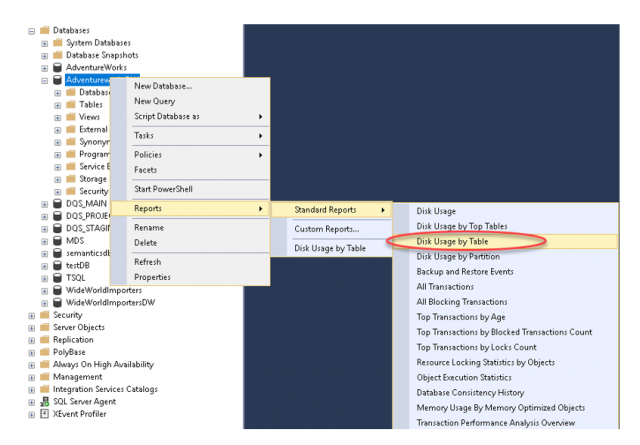
จะได้ผลลัพธ์ ดังแสดง
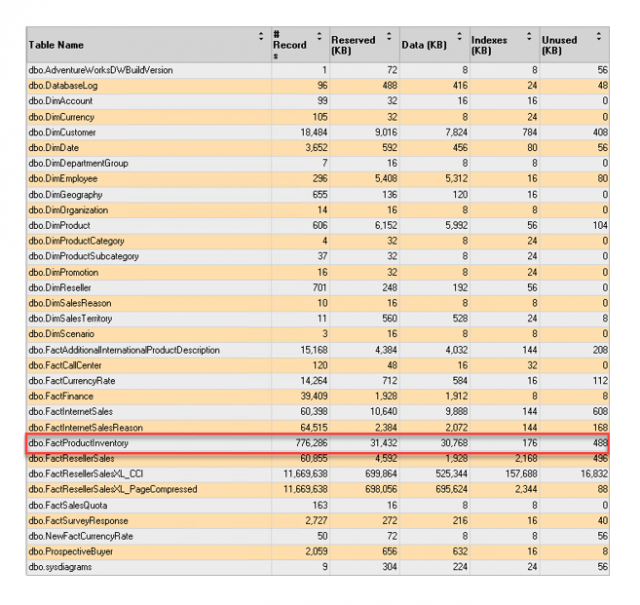
ผู้เขียนเลือกใช้ตาราง dbo.FactProductInventory เพราะมีขนาดพอเหมาะ
เราสามารถปรับแต่งตารางให้เหมาะกับการทดสอบโดยทำการลบ Primary Key แบบ Clustered ทิ้งไป
แล้วสร้างใหม่เป็นแบบ Non-Clustered เพื่อให้สามารถสร้าง Clustered Columnstore Index ขึ้นมาใช้งานได้
ดังสคริปต์ต่อไปนี้
จากนั้นผู้เขียนทำการสร้าง Stored Procedure ให้สืบค้นข้อมูลจากตารางที่เตรียมไว้
โดยให้มีประโยค Order By เพื่อเกิดตัวดำเนินการ Sort ดังสคริปต์ต่อไปนี้
เราสามารถปรับแต่งตารางให้เหมาะกับการทดสอบโดยทำการลบ Primary Key แบบ Clustered ทิ้งไป
แล้วสร้างใหม่เป็นแบบ Non-Clustered เพื่อให้สามารถสร้าง Clustered Columnstore Index ขึ้นมาใช้งานได้
ดังสคริปต์ต่อไปนี้
/*---------------------------------------------------------------- Prepare Database and Table for Batch Mode Memory Grant Feedback Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ USE AdventureworksDW; GO ALTER DATABASE AdventureworksDW SET COMPATIBILITY_LEVEL = 140; --2017 GO ALTER TABLE dbo.FactProductInventory DROP CONSTRAINT PK_FactProductInventory; GO ALTER TABLE dbo.FactProductInventory ADD CONSTRAINT PK_FactProductInventory PRIMARY KEY NONCLUSTERED (ProductKey ASC, DateKey ASC); GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_FactProductInventory ON dbo.FactProductInventory; GO
จากนั้นผู้เขียนทำการสร้าง Stored Procedure ให้สืบค้นข้อมูลจากตารางที่เตรียมไว้
โดยให้มีประโยค Order By เพื่อเกิดตัวดำเนินการ Sort ดังสคริปต์ต่อไปนี้
/*---------------------------------------------------------------- Testing Procedure for Batch Mode Memory Grant Feedback Script By: Phakkhaphong Krittawat (Data Meccanica Co.,Ltd.) Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ CREATE OR ALTER PROCEDURE dbo.udp_GetProductInventoryAboveCost @cost int AS SELECT I.* FROM dbo.FactProductInventory as I INNER JOIN dbo.DimDate as D ON I.DateKey=D.DateKey WHERE D.CalendarYear>=2009 AND I.UnitCost>@cost ORDER BY I.ProductKey,I.UnitCost DESC OPTION (MAXDOP 1);ก่อนทำการทดสอบให้เลือก Include Actual Execution Plan จากนั้น Execute สคริปต์ต่อไปนี้
/*---------------------------------------------------------------- Testing Round #1 Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO EXEC dbo.udp_GetProductInventoryAboveCost @cost=5000;ผลลัพธ์ที่ได้คือ
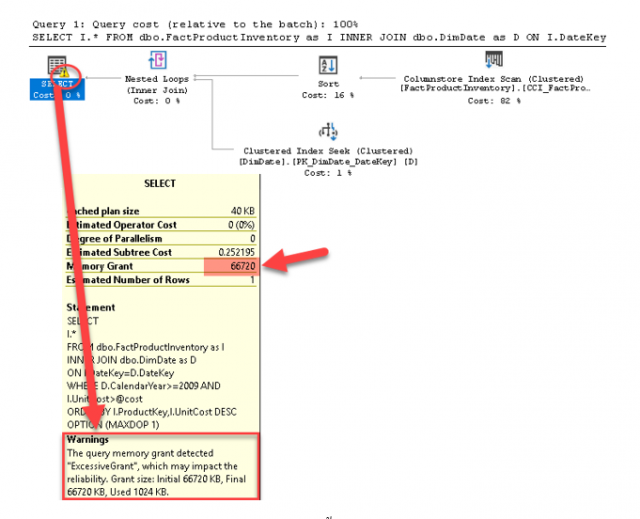
พารามิเตอร์ @cost=5000 ที่ส่งให้กับ Stored Procedure นั้น ไม่ได้แถวข้อมูลแม้แต่แถวเดียว
ระบบตรวจสอบพบว่ามีการจัดสรรขนาดความจุของหน่วยความจำมากเกินไป คือ 66,720 KB ขณะที่ใช้งานเพียง 1,024 KB
จากนั้นผู้เขียนทำการทดสอบในรอบต่อไปโดยจะไม่ทำการล้าง Cached Plan ของ Stored Procedure
ในรอบนี้ผุ้เขียนจะใช้พารามิเตอร์ @cost=500 ส่งให้กับ Stored Procedure ดังสคริปต์ต่อไปนี้
ก่อนทำการทดสอบให้เลือก Include Actual Execution Plan จากนั้น Execute สคริปต์
ผลลัพธ์ที่ได้คือ
ระบบตรวจสอบพบว่ามีการจัดสรรขนาดความจุของหน่วยความจำมากเกินไป คือ 66,720 KB ขณะที่ใช้งานเพียง 1,024 KB
จากนั้นผู้เขียนทำการทดสอบในรอบต่อไปโดยจะไม่ทำการล้าง Cached Plan ของ Stored Procedure
ในรอบนี้ผุ้เขียนจะใช้พารามิเตอร์ @cost=500 ส่งให้กับ Stored Procedure ดังสคริปต์ต่อไปนี้
ก่อนทำการทดสอบให้เลือก Include Actual Execution Plan จากนั้น Execute สคริปต์
/*---------------------------------------------------------------- Testing Round #2 Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ EXEC dbo.udp_GetProductInventoryAboveCost @cost=500;
ผลลัพธ์ที่ได้คือ
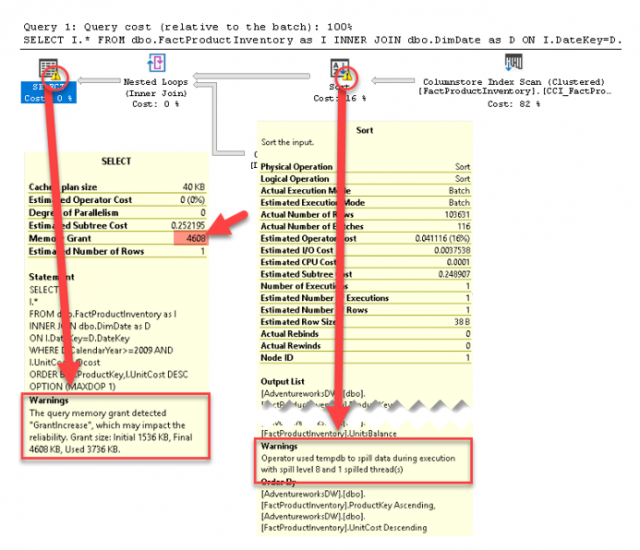
พบว่ามีการจัดสรรขนาดความจุของหน่วยความจำน้อยเกินไป จนต้องมีการจัดสรรเพิ่มจาก คือ 1,536 KB ไปเป็น 4,608 KB ขณะที่ตัวดำเนิน Sort พบว่ามีแถวข้อมูลจำนวนหนึ่งที่เกินความจุของหน่วยความจำรั่วไหลลงสู่ดิสก์ (Spill to Disk) ในส่วนของฐานข้อมูล tempdb จากนั้นผู้เขียนทำการทดสอบในรอบสุดท้าย โดยจะไม่ทำการล้าง Cached Plan ของ Stored Procedure เช่นกัน และยังคงใช้พารามิเตอร์ @cost=500 ส่งให้กับ Stored Procedure เพื่อทดสอบว่ากลไก Batch Mode Memory Grant Feedback ได้ทำการปรับปรุง Grant Value ให้กับ Cached Plan หรือไม่ ดังสคริปต์ต่อไปนี้
ก่อนทำการทดสอบให้เลือก Include Actual Execution Plan จากนั้น Execute สคริปต์
ผลลัพธ์ที่ได้คือ
ก่อนทำการทดสอบให้เลือก Include Actual Execution Plan จากนั้น Execute สคริปต์
/*---------------------------------------------------------------- Testing Round #3 Script By: 9Expert Training Modified Date: Jan 27, 2018 ----------------------------------------------------------------*/ EXEC dbo.udp_GetProductInventoryAboveCost @cost=500;
ผลลัพธ์ที่ได้คือ
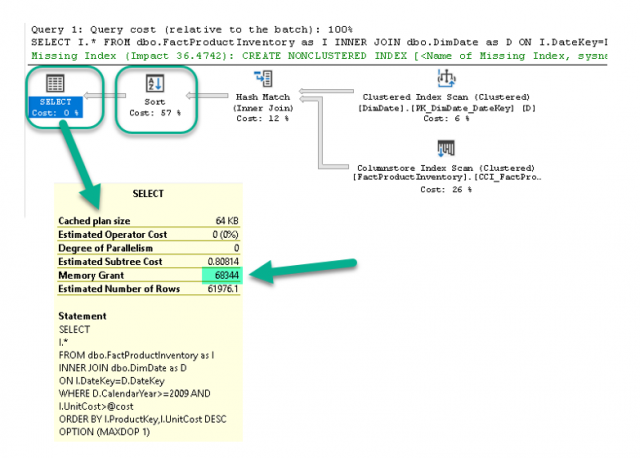
พบว่ากลไก Batch Mode Memory Grant Feedback ได้ทำการปรับปรุง Grant Value ให้เหมาะสม
โดยไม่มีแถวข้อมูลไปลงใน
ที่กล่าวมาเกี่ยวกับ Adaptive Query processing ซึ่งประกอบด้วย Interleaved Execution, Batch mode adaptive join และ Batch mode memory grant feedback นั้นผู้อ่านไม่ต้องปรับแต่งค่าอะไรเป็นพิเศษเพียงแค่ใช้งานบน Microsoft SQL Server 2017 และตรวจสอบให้แน่ใจว่าฐานข้อมูลกำหนด Compatibility Level ไว้เป็น Microsoft SQL Server 2017 ด้วย เพียงเท่านี้คุณสมบัติของ Adaptive Query processing ก็จะทำงานโดยอัตโนมัติ
Automatic Plan Correction
ก่อนหน้านี้ Microsoft SQL Server 2016 ได้มีการคุณสมบัติเพิ่มเติมที่เรียกว่า Query Store ซึ่งเราสามารถวิเคราะห์ว่า Query มีการเลือกใช้ Execution Plan ที่ให้ประสิทธิภาพถดถอยลง และสามารถนำเอา Plan เก่ามาบังคับใช้ แล้ววิเคราะห์ว่าประสิทธิภาพจะกลับมาดีหรือไม่
ผู้เขียนเคยเขียนบทความเกี่ยวกับ Query Store เอาไว้แล้ว สามารถอ่านได้จาก “รู้จัก Query Store บน SQL Server 2016”
สำหรับ Automatic Plan Correction บน Microsoft SQL Server 2017 เหมือนเป็นการต่อยอด เพราะ Microsoft SQL Server จะคอยติดตามว่ามี Plan ใหม่ของ Query เดิมเกิดขึ้นหรือไม่
หรือเกิดขึ้นแย่กว่าของเดิมหรือไม ถ้าแย่กว่าให้นำ Plan เดิมกับมา
โดยจะเรียก Plan เดิมที่นำกลับมาใช้ว่า Last Know Good Plan
โดยสามารถเปิดคุณสมบัติดังกล่าวด้วยคำสั่งต่อไปนี้
ฐานข้อมูลจะต้องเปิดใช้ Query Store ก่อนที่จะเปิดคุณสมบัตินี้
โดยไม่มีแถวข้อมูลไปลงใน
ที่กล่าวมาเกี่ยวกับ Adaptive Query processing ซึ่งประกอบด้วย Interleaved Execution, Batch mode adaptive join และ Batch mode memory grant feedback นั้นผู้อ่านไม่ต้องปรับแต่งค่าอะไรเป็นพิเศษเพียงแค่ใช้งานบน Microsoft SQL Server 2017 และตรวจสอบให้แน่ใจว่าฐานข้อมูลกำหนด Compatibility Level ไว้เป็น Microsoft SQL Server 2017 ด้วย เพียงเท่านี้คุณสมบัติของ Adaptive Query processing ก็จะทำงานโดยอัตโนมัติ
Automatic Plan Correction
ก่อนหน้านี้ Microsoft SQL Server 2016 ได้มีการคุณสมบัติเพิ่มเติมที่เรียกว่า Query Store ซึ่งเราสามารถวิเคราะห์ว่า Query มีการเลือกใช้ Execution Plan ที่ให้ประสิทธิภาพถดถอยลง และสามารถนำเอา Plan เก่ามาบังคับใช้ แล้ววิเคราะห์ว่าประสิทธิภาพจะกลับมาดีหรือไม่
ผู้เขียนเคยเขียนบทความเกี่ยวกับ Query Store เอาไว้แล้ว สามารถอ่านได้จาก “รู้จัก Query Store บน SQL Server 2016”
สำหรับ Automatic Plan Correction บน Microsoft SQL Server 2017 เหมือนเป็นการต่อยอด เพราะ Microsoft SQL Server จะคอยติดตามว่ามี Plan ใหม่ของ Query เดิมเกิดขึ้นหรือไม่
หรือเกิดขึ้นแย่กว่าของเดิมหรือไม ถ้าแย่กว่าให้นำ Plan เดิมกับมา
โดยจะเรียก Plan เดิมที่นำกลับมาใช้ว่า Last Know Good Plan
โดยสามารถเปิดคุณสมบัติดังกล่าวด้วยคำสั่งต่อไปนี้
ALTER DATABASE Adventureworks SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON )
ฐานข้อมูลจะต้องเปิดใช้ Query Store ก่อนที่จะเปิดคุณสมบัตินี้
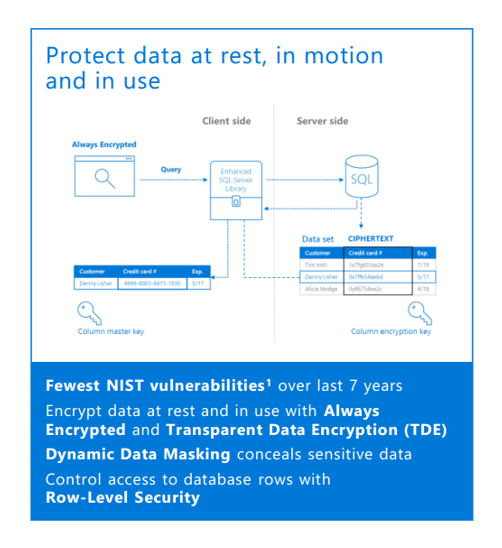
ความปลอดภัยของข้อมูล
สำหรับเทคโนโลยีด้านความปลอดภัยไม่ว่าจะเป็น- Always Encrypted,
- Transparent Data Encryption,
- Dynamic Data Masking หรือ
- Row-Level Security
หากผู้อ่านสนใจสามารถเข้าฝึกอบรมในหลักสูตร Microsoft SQL Server 2017 Database Administration กับทางสถาบัน 9Expert
ผู้เขียนจะขอขยายความที่ Microsoft กล่าวอ้างว่า Microsoft SQL Server มีช่องโหว่น้อยที่สุด ตลอด 7 ปีที่ผ่านมา เป็นเรื่องจริงหรือไม่
ทาง Microsoft ออกเอกสารเผยแพร่ว่าผลิตภัณฑ์ Microsoft SQL Server ของตนมีช่องโหว่ต่ำที่สุดมาตลอด
ในเอกสารยังอ้างถึง NIST (National Institute of Standards and Technology) ซึ่งเป็นสถาบันมาตรฐานของสหรัฐอเมริกา โดยทาง NIST ได้สร้าง NVD (National Vulnerability Database) ซึ่งนำเอา CVE (Common Vulnerabilities and Exposures) มาต่อยอด
หากใครอยู่ในแวดวง Security คงคุ้นกับ CVE กันอยู่แล้ว เพราะไม่ว่าใครในโลกค้นพบช่องโหว่เกิดใหม่ก็จะส่งไปให้ CVE ตรวจสอบ ออกหมายเลข CVE Number กำกับช่องโหว่นั้น ๆ และเผยแพร่ช่องโหว่สู่สาธารณะ
ที่บอกว่า NIST ได้นำเอา CVE มาต่อยอด เพราะนำ
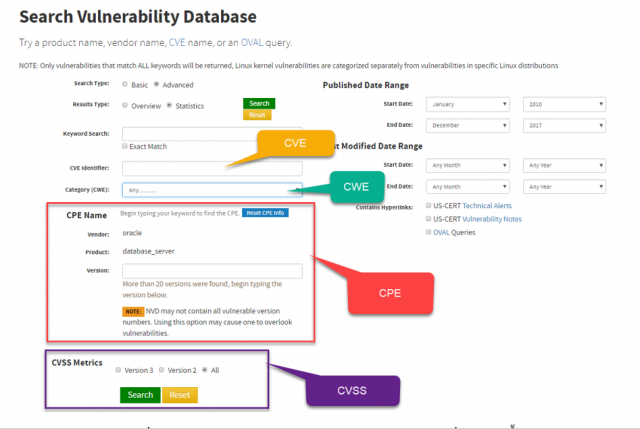
- CVSS (The Common Vulnerability Scoring System) ใช้ระบุระดับความรุนแรงของช่องโหว่,
- CPE (Common Platform Enumeration) ใช้ระบุแพลตฟอร์มและเวอร์ชั่นที่เกิดช่องโหว่ และ
- CWE (The Common Weakness Enumeration) ระบุถึงประเภทของช่องโหว่
ผู้เขียนจะสืบค้นช่องโหว่ของ Oracle ย้อนหลังไป 7 ปี ตั้งแต่ปี 2010-2017 สามารถทำได้โดย ไปที่ https://nvd.nist.gov/vuln/search กำหนด เป็น Oracle Database Server ลงในส่วนของ CPE ดังแสดง
แล้วเลือกแสดงผลลัพธ์เป็นตัวเลขสถิติ ระบบจะทำการ Count จำนวน CVE ในช่วงตั้งแต่ปี 2010-2017 ออกมาแสดง
และทำแบบเดียวกันโดยเปลี่ยนผลิตภัณฑ์เป็น Mysql และ Microsoft SQL Server
ผลที่ได้เป็นดังนี้
ผลที่ได้เป็นดังนี้
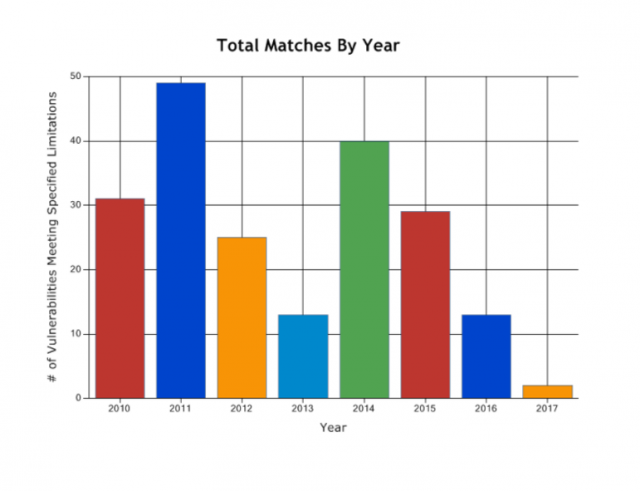
ช่องโหว่ของ Oracle ในช่วงปี 2010-2017
ช่องโหว่ของ MySQL ในช่วงปี 2010-2017
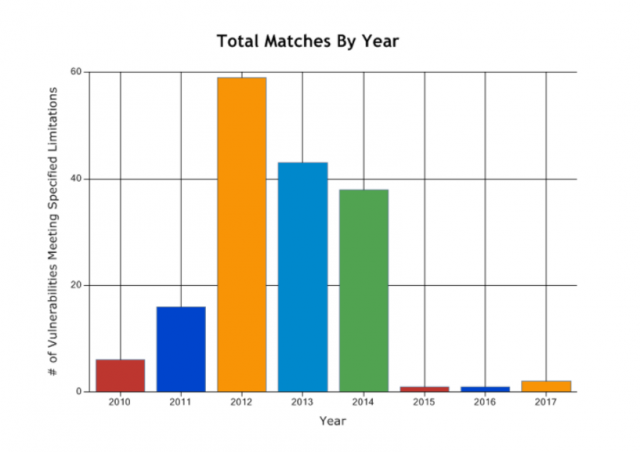
ช่องโหว่ของ Microsoft SQL Server ในช่วงปี 2010-2017
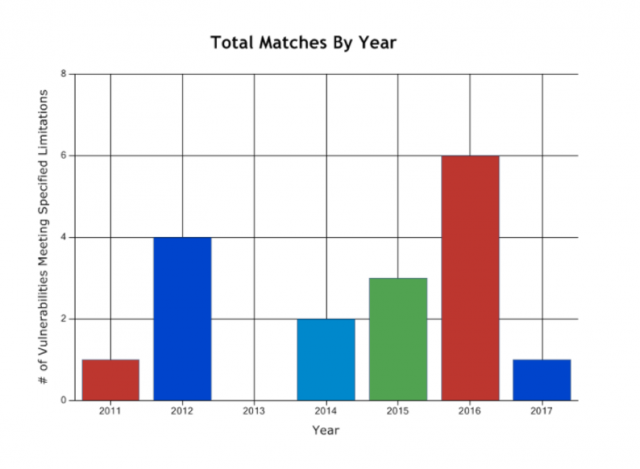
จากกราฟก็น่าจะเป็นความจริง เพราะจำนวนช่องโหว่ของ Microsoft SQL Server ตลอด 7 ปี
ไม่เคยมีไหนเลยที่เกิน 10 และมีเกิน 5 เพียงปีเดียวเท่านั้น
ต่างจาก Oracle ที่มีจำนวนช่องโหว่เกิน 10 แทบทุกปี และเกิน 20 เสียเป็นส่วนใหญ่
ไม่เคยมีไหนเลยที่เกิน 10 และมีเกิน 5 เพียงปีเดียวเท่านั้น
ต่างจาก Oracle ที่มีจำนวนช่องโหว่เกิน 10 แทบทุกปี และเกิน 20 เสียเป็นส่วนใหญ่
จำนวนช่องโหว่ของ Microsoft SQL Server ลดลงทันที 90% ตั้งแต่ Microsoft SQL Server 2005
ซึ่งเป็นเวอร์ชันแรกที่ Microsoft นำเอา Security Development Lifecycle https://www.microsoft.com/en-us/SDL/ มาใช้งาน
ซึ่งเป็นเวอร์ชันแรกที่ Microsoft นำเอา Security Development Lifecycle https://www.microsoft.com/en-us/SDL/ มาใช้งาน
CVE,CPE และ CWE เป็นโปรเจคภายใต้การดูแลของ MITRE Corporation ซึ่งเป็นองค์กรไม่แสวงกำไรทำหน้าที่สนับสนุนโครงงานวิจัยและพัฒนา โดยเงินสนับสนุน หรือ FFRDCs (Federally Funded Research and Development Centers) ได้รับมาจากรัฐบาลกลางของสหรัฐอเมริกา CVSS ได้รับการพัฒนาจากคณะทำงานที่ชื่อว่า CVSS Special Interest Group (SIG) ภายใต้การดูแลของ FIRST(Forum of Incident Response and Security Teams) เป็นศูนย์กลางในการแลกเปลี่ยนข้อมูลให้ความรู้ทางด้านความมั่นคงปลอดภัย และพัฒนาแนวทางในการรับมือกับภัยคุกคามทางคอมพิวเตอร์ระหว่างหน่วยงาน Incident Response จากประเทศต่าง ๆ ทั่วโลก ปัจจุบันมีถึง 409 หน่วยงาน จาก 84 ประเทศ สำหรับประเทศไทยก็มี THAICERT (Thailand Computer Emergency Response Team) ภายใต้กำกับของ สำนักงานพัฒนาธุรกรรมทางอิเล็กทรอนิกส์ (องค์การมหาชน) ร่วมเป็นสมาชิกด้วย
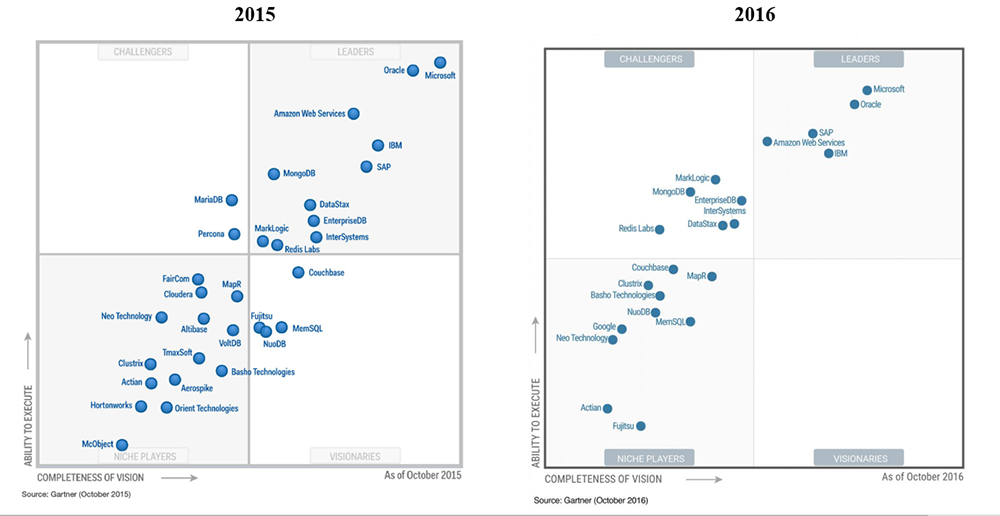
In-Memory OLTP ครอบคลุมทั่วถึง
In-Memory OLTP มีใช้งานมาตั้งแต่ Microsoft SQL Server 2014 และทำให้ Microsoft SQL Server มีประสิทธิภาพเหนือคู่แข่งอย่าง Oracle
โดยอ้างอิงจากผลวิจัยในเอกสาร Magic Quadrant ของ Gartner ในปี 2015-2016
สำหรับ Microsoft SQL Server 2017 ไม่มีคุณสมบัติใหม่ที่โดดเด่นเพิ่มเติม แต่เป็นการปรับปรุงด้านประสิทธิภาพ
และขจัดข้อจำกัดต่าง ๆ ให้แก่ Memory-Optimized Tables และ Natively Compiled Stored Procedures
ส่วนที่บอกว่าครอบคลุมทั่วถึงอาจเป็นเพราะมีการเพิ่มคุณสมบัติให้สามารถจัดเก็บไฟล์ Memory-Optimized สามารถจัดเก็บไว้บน Azure Storage
และยังสามารถ Backup หรือ Restore ไฟล์ Memory-Optimized จาก On-Premise ไปยัง Azure Storage ได้
มีความสอดประสานกันใน Microsoft Data Platform
ในเรื่องนี้ก็ไม่ใช่เรื่องใหม่สำหรับ Microsoft เหตุผลหนึ่งที่ผลวิจัยในเอกสาร Magic Quadrant ของ Gartner
ให้ Microsoft SQL Server ชนะในด้านวิสัยทัศน์ ก็เป็นการทำงานสอดประสานกันใน Microsoft Data Platform
ก่อนอื่นต้องบอกว่า Microsoft SQL Server 2017 ไม่ใช่ผลิตภัณฑ์เดียวในกลุ่ม Data Platform
สำหรับในด้านการจัดการฐานข้อมูล นอกจาก Microsoft SQL Server แล้วก็จะมี
ไม่ว่าจะเป็นการใช้งานข้อมูลร่วมกัน การใช้งานเสริมกันเพื่อเพิ่มความแข่งแกร่ง
และความสามารถในการใช้งานได้ทุกหนแห่ง รวมถึงความสามารถในการทำ Offsite Backup แบบเร่งด่วนเป็นต้น
นอกเหนือจากด้านการจัดการฐานข้อมูล Microsoft Data Platform ก็มีผลิตภัณฑ์ด้าน Analytics
ซึ่ง Microsoft SQL Server 2017 ก็เข้ามาอยู่ในกลุ่มนี้ด้วย
ตั้งแต่ Microsoft SQL Server 2016 ที่มีการใส่ภาษา R และใน Microsoft SQL Server 2017 ที่มีการใส่ภาษา Python เข้ามา
เพื่อให้สามารถทำ Analytics ได้บนตัว Microsoft SQL Server เลย ทำให้ถูกจัดเป็นผลิตภัณฑ์ในด้านนี้ด้วย
ผู้เขียนจะยกมาเล่าให้ฟังใหม่ในตอนที่ 2 ซึ่งมีใน Infographic เหลืออีก 3 กล่องด้วยกัน หนึ่งในนั้นมีเรื่องของ Advanced Analytics อยู่ด้วย
In-Memory OLTP มีใช้งานมาตั้งแต่ Microsoft SQL Server 2014 และทำให้ Microsoft SQL Server มีประสิทธิภาพเหนือคู่แข่งอย่าง Oracle
โดยอ้างอิงจากผลวิจัยในเอกสาร Magic Quadrant ของ Gartner ในปี 2015-2016
สำหรับ Microsoft SQL Server 2017 ไม่มีคุณสมบัติใหม่ที่โดดเด่นเพิ่มเติม แต่เป็นการปรับปรุงด้านประสิทธิภาพ
และขจัดข้อจำกัดต่าง ๆ ให้แก่ Memory-Optimized Tables และ Natively Compiled Stored Procedures
ส่วนที่บอกว่าครอบคลุมทั่วถึงอาจเป็นเพราะมีการเพิ่มคุณสมบัติให้สามารถจัดเก็บไฟล์ Memory-Optimized สามารถจัดเก็บไว้บน Azure Storage
และยังสามารถ Backup หรือ Restore ไฟล์ Memory-Optimized จาก On-Premise ไปยัง Azure Storage ได้
มีความสอดประสานกันใน Microsoft Data Platform
ในเรื่องนี้ก็ไม่ใช่เรื่องใหม่สำหรับ Microsoft เหตุผลหนึ่งที่ผลวิจัยในเอกสาร Magic Quadrant ของ Gartner
ให้ Microsoft SQL Server ชนะในด้านวิสัยทัศน์ ก็เป็นการทำงานสอดประสานกันใน Microsoft Data Platform
ก่อนอื่นต้องบอกว่า Microsoft SQL Server 2017 ไม่ใช่ผลิตภัณฑ์เดียวในกลุ่ม Data Platform
สำหรับในด้านการจัดการฐานข้อมูล นอกจาก Microsoft SQL Server แล้วก็จะมี
- Azure Database สำหรับ Microsoft SQL Server ปัจจุบันเรียกว่า SQL Database
- Azure Database สำหรับ MySQL
- Azure Database สำหรับ PostgreSQL
- SSAS บน Azure ปัจจุบันเรียกว่า SQL Data Warehouse
- และ Azure Cosmos DB
ไม่ว่าจะเป็นการใช้งานข้อมูลร่วมกัน การใช้งานเสริมกันเพื่อเพิ่มความแข่งแกร่ง
และความสามารถในการใช้งานได้ทุกหนแห่ง รวมถึงความสามารถในการทำ Offsite Backup แบบเร่งด่วนเป็นต้น
นอกเหนือจากด้านการจัดการฐานข้อมูล Microsoft Data Platform ก็มีผลิตภัณฑ์ด้าน Analytics
ซึ่ง Microsoft SQL Server 2017 ก็เข้ามาอยู่ในกลุ่มนี้ด้วย
ตั้งแต่ Microsoft SQL Server 2016 ที่มีการใส่ภาษา R และใน Microsoft SQL Server 2017 ที่มีการใส่ภาษา Python เข้ามา
เพื่อให้สามารถทำ Analytics ได้บนตัว Microsoft SQL Server เลย ทำให้ถูกจัดเป็นผลิตภัณฑ์ในด้านนี้ด้วย
ผู้เขียนจะยกมาเล่าให้ฟังใหม่ในตอนที่ 2 ซึ่งมีใน Infographic เหลืออีก 3 กล่องด้วยกัน หนึ่งในนั้นมีเรื่องของ Advanced Analytics อยู่ด้วย
บทความโดย
อาจารย์ภัคพงศ์ กฤตวัฒน์
- วิทยากรผู้ดูแลและออกแบบหลักสูตร
- กลุ่มวิชา SQL Server/Window Server
- Microsoft SQL Server Specialist
- Microsoft Certified Trainer (2002-Present)
- Co-Founder at Data Meccanica Co., Ltd.
บทความที่เกี่ยวข้อง