




เตรียมพร้อมก่อนอ่าน Execution Plan
เตรียมพร้อมก่อนอ่าน Execution Plan
มีคนถามเข้ามาพอสมควรเวลาที่ผู้เขียนแสดง Query Execution Plan และวิเคราะห์ประสิทธิภาพให้ฟัง ทั้งในหลักสูตรที่ผู้เขียนบรรยายหรือสรุปผลประสิทธิภาพให้ลูกค้าฟังส่วนใหญ่อยากทราบว่ารายละเอียดของแต่ละตัวดำเนินการที่แสดงหมายถึงอะไร ผู้เขียนก็อยากจะเล่ามันทุกตัว
แต่บางครั้งมันเล่ายากมาก เพราะหลายๆ ตัวต้องรู้ถึงโครงสร้างตารางทั้งแบบ Rowstore และ Columnstore
ต้องรู้ถึงโครงสร้าง Indexes ทั้งแบบ Rowstore และ Columnstore เช่นกัน
อีกทั้งยังต้องเข้าใจลำดับการประมวลผลของคำสั่ง เข้าใจถึงการเกิด Parallelism จิปาถะไปหมด
ผู้เขียนจึงขอเริ่มจากการทำความเข้าใจ ขั้นตอนการประมวลผลคิวรี่ กันก่อนดีกว่า
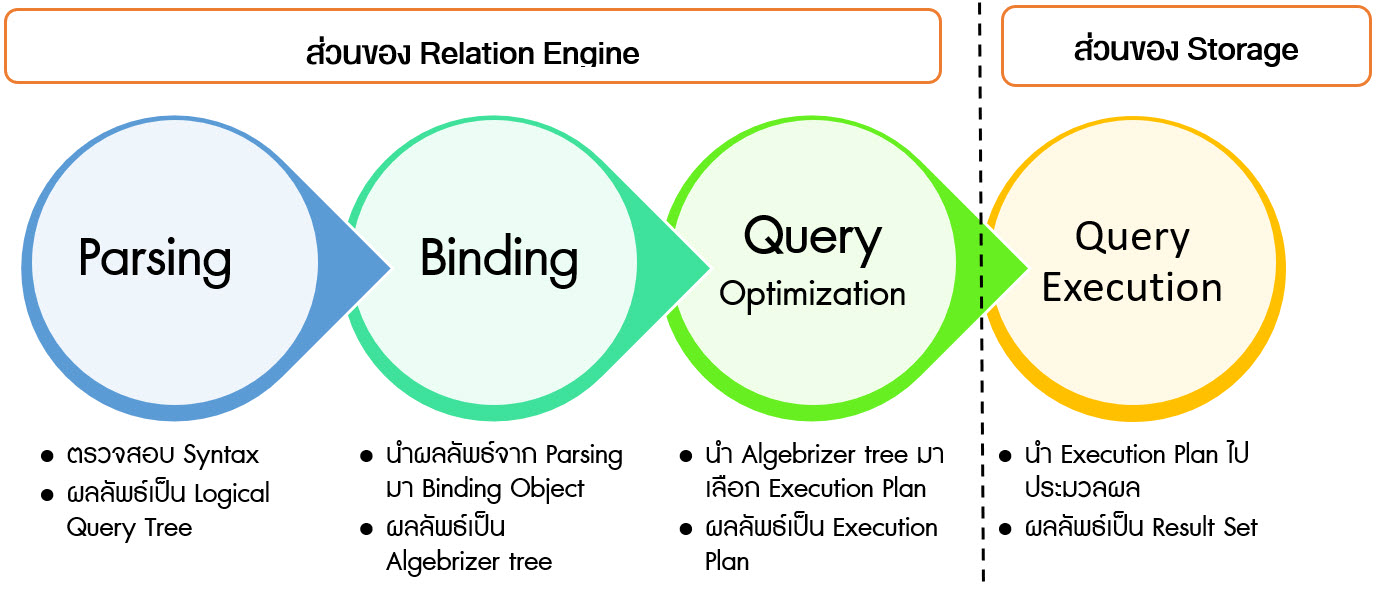
ขั้นตอนที่ 1 Parsing
เป็นหน้าที่ของคอมโพเนนต์ใน SQL Server Relation Engine ชื่อว่า Parserทำหน้าที่วิเคราะห์และตรวจสอบ Syntax ของคำสั่งที่ส่งเข้ามา และแยกองค์ประกอบของคำสั่งไปสร้างเป็น Logical Query Tree
เราสามารถทดสอบขั้นตอนนี้ผ่านทาง Microsoft SQL Server Management Studio (SSMS)
โดยทดลองส่งคำสั่ง SELECT ต่อไปนี้ (ผู้เขียนใช้ฐานข้อมูล Adventureworks ในการทดสอบ)
จากนั้นกด Ctrl-F5
SELECT
O.SalesOrderID
, YEAR(O.OrderDate)
, SUM(OD.UnitPrice*OD.UnitPrice*(1-OD.UnitPriceDiscount)) as Amount
FROM Sales.SalesOrderHeader as O
INNER JOIN Sales.SalesOrderDetail as OD
ON O.SalesOrderID=OD.SalesOrderID
GROUP BY O.SalesOrderID;
ผลลัพธ์ที่ได้ดังแสดง
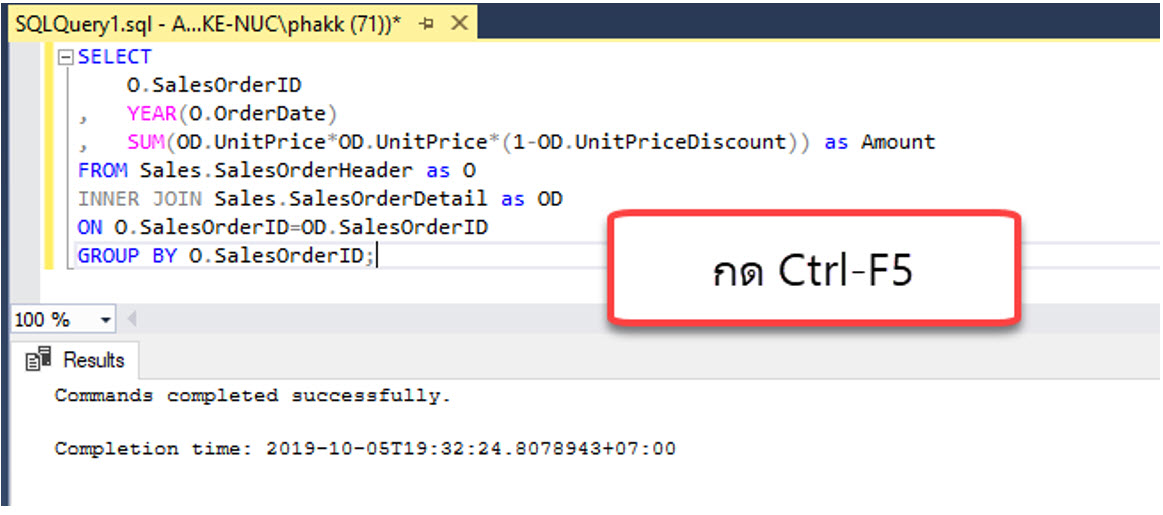
หากแสดงข้อความ “Commands completed successfully” แสดงว่าเป็นคำสั่งที่มี Syntax ถูกต้อง
แต่เมื่อกดปุ่ม F5 เพื่อ Execute จริง ผลลัพธ์ที่ได้กลับแสดงข้อผิดพลาดดังแสดง
แต่เมื่อกดปุ่ม F5 เพื่อ Execute จริง ผลลัพธ์ที่ได้กลับแสดงข้อผิดพลาดดังแสดง
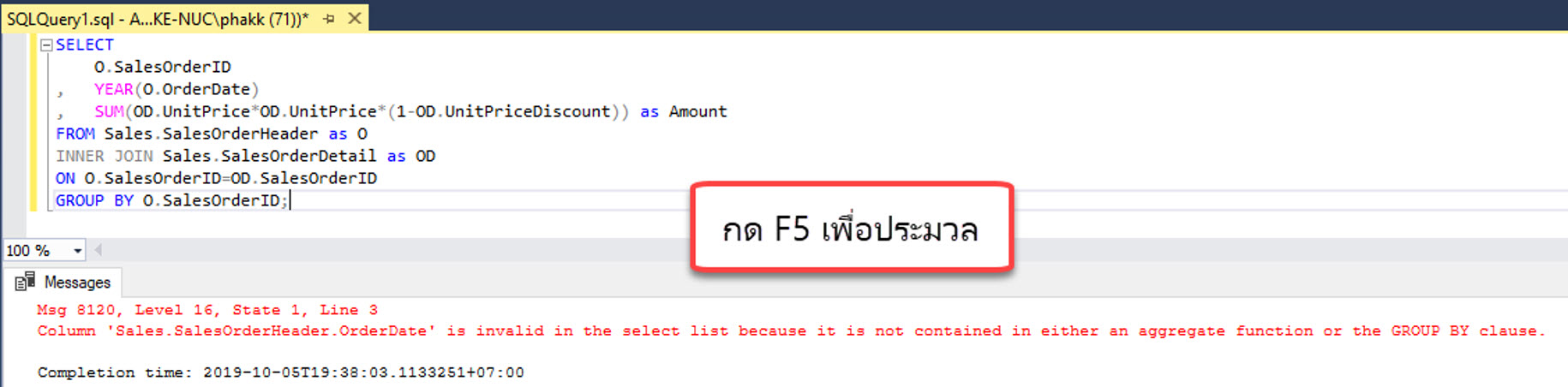
เพราะ Parser ทำหน้าที่เพียงตรวจ Syntax ของคำสั่งเท่านั้น
แต่เรื่องของกฎเกณฑ์ของประโยค GROUP BY เป็นงานลำดับถัดไป
ทำหน้าที่นำ Logical Query Tree ที่ได้จากขั้นตอน Parsing มาตรวจสอบดังนี้
เป็นขั้นตอนสุดท้ายของการทำ Plan Compilation และ สามารถข้ามขั้นตอน นี้ไปได้หาก Plan ของคิวรี่ที่กำลังดำเนินการถูก Complied และเก็บเอาไว้ใน Plan Cache เรียบร้อยแล้ว (จัดเก็บลงหน่วยความจำ เป็นส่วนหนึ่งของ SQL Server Buffer) ก็สามารถนำ Complied Plan ส่งต่อไปประมวลผลที่ Storage Engine ได้เลย
แต่ถ้าหากไม่มี Complied Plan อยู่ใน Plan Cache ก็จะเริ่มขั้นตอนของ Query Optimization ต่อไป
แต่เรื่องของกฎเกณฑ์ของประโยค GROUP BY เป็นงานลำดับถัดไป
ขั้นตอนที่ 2 Binding
เป็นหน้าที่ของคอมโพเนนต์ใน SQL Server Relation Engine ชื่อว่า Algebrizerทำหน้าที่นำ Logical Query Tree ที่ได้จากขั้นตอน Parsing มาตรวจสอบดังนี้
- ตรวจสอบ Database Objects อาทิ ตาราง, คอลัมน์ภายในตาราง ว่ามีอยู่จริง
- ตรวจสอบสิทธิ์การเข้าถึง Database Objects ว่าเข้าถึงได้หรือไม่
- ระบุชนิดข้อมูลของแต่ละคอลัมน์
- ตรวจสอบประโยค GROUP BY ร่วมกับคอลัมน์ที่ระบุใน Aggregate Function ว่าถูกต้องตามกฎหรือไม่
ขั้นตอนที่ 3 Query Optimization
เป็นหน้าที่ของคอมโพเนนต์ใน SQL Server Relation Engine ชื่อว่า Query Optimizerเป็นขั้นตอนสุดท้ายของการทำ Plan Compilation และ สามารถข้ามขั้นตอน นี้ไปได้หาก Plan ของคิวรี่ที่กำลังดำเนินการถูก Complied และเก็บเอาไว้ใน Plan Cache เรียบร้อยแล้ว (จัดเก็บลงหน่วยความจำ เป็นส่วนหนึ่งของ SQL Server Buffer) ก็สามารถนำ Complied Plan ส่งต่อไปประมวลผลที่ Storage Engine ได้เลย
แต่ถ้าหากไม่มี Complied Plan อยู่ใน Plan Cache ก็จะเริ่มขั้นตอนของ Query Optimization ต่อไป
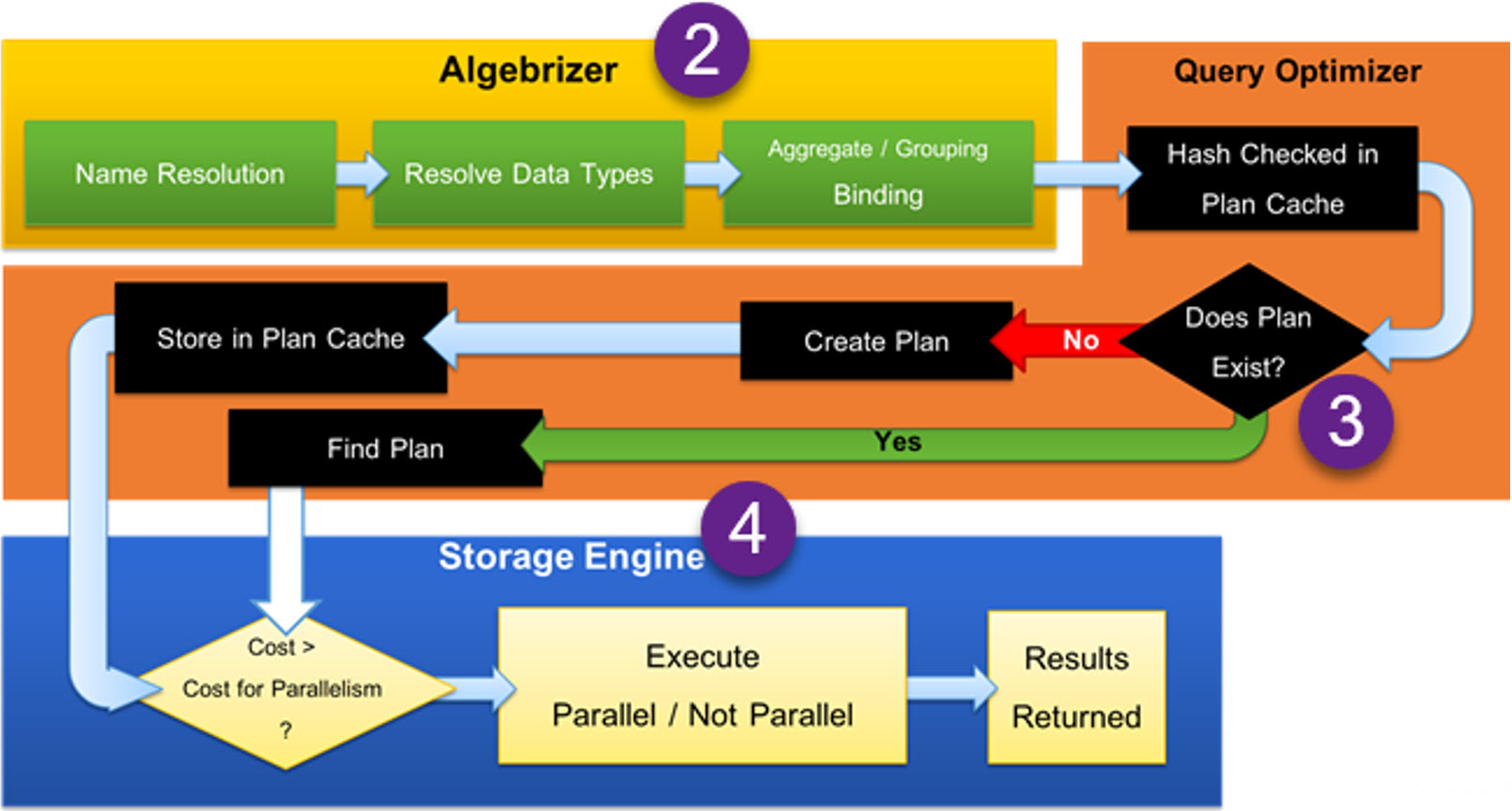
ขั้นตอนภายใน Query Optimization
Query Optimizer ดำเนินการผ่านหลายขั้นตอนที่ออกแบบมาเพื่อเพิ่มประสิทธิภาพการคิวรี่ให้เร็วที่สุด
โดยหลีกเลี่ยงตัวเลือกที่เสีย Cost มากและซับซ้อนเกินจำเป็น โดยมีขั้นตอนดังนี้
Query Optimizer ดำเนินการผ่านหลายขั้นตอนที่ออกแบบมาเพื่อเพิ่มประสิทธิภาพการคิวรี่ให้เร็วที่สุด
โดยหลีกเลี่ยงตัวเลือกที่เสีย Cost มากและซับซ้อนเกินจำเป็น โดยมีขั้นตอนดังนี้
- ขั้นตอน Simplification
ลดรูปคิวรี่ให้อยู่ในรูปแบบที่ง่ายขึ้น และได้ประสิทธิภาพดีกว่า รวมถึง- การแปลงคิวรี่ย่อย (Subqueries) ให้อยู่ในรูปแบบของการ JOIN ปกติ
- ลดการ JOIN ที่ซ้ำซ้อนลง
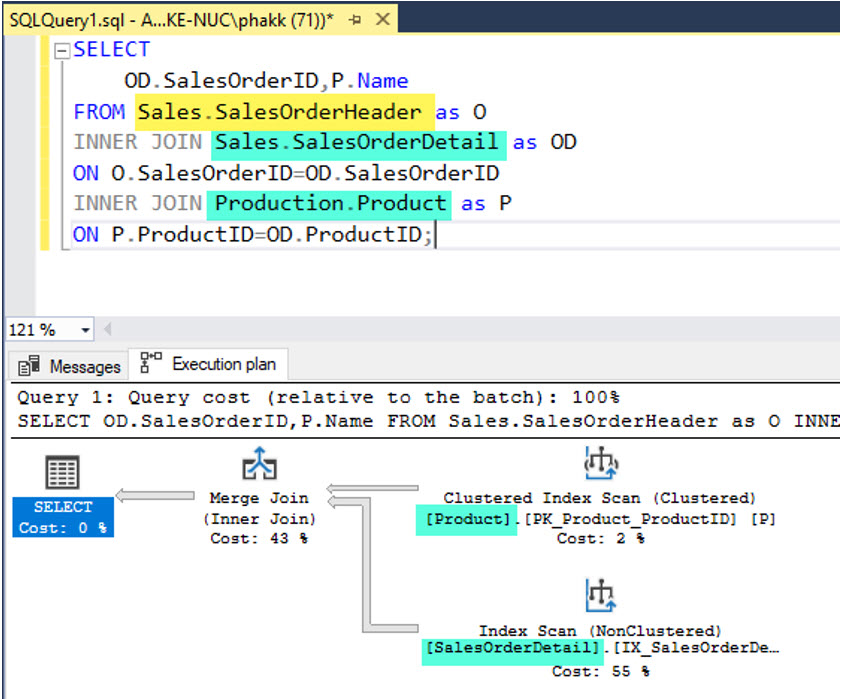
จากรูป เป็น ตัวอย่างขั้นตอน Simplification จะเห็นว่าคิวรี่มีตารางที่ JOIN กันถึง 3 ตาราง คือ
Sales.SalesOrderHeader,
Sales.SalesOrderDetails และ
Production.Product
แต่ Plan ที่ถูกเลือกนำมาใช้เหลือแค่ 2 ตาราง คือตาราง Sales.SalesOrderDetails และ Production.Product เท่านั้น
เพราะคอลัมน์ใน SELECT List ไม่มีความจำเป็นต้องใช้ข้อมูลจากตาราง Sales.SalesOrderHeader
Sales.SalesOrderHeader,
Sales.SalesOrderDetails และ
Production.Product
แต่ Plan ที่ถูกเลือกนำมาใช้เหลือแค่ 2 ตาราง คือตาราง Sales.SalesOrderDetails และ Production.Product เท่านั้น
เพราะคอลัมน์ใน SELECT List ไม่มีความจำเป็นต้องใช้ข้อมูลจากตาราง Sales.SalesOrderHeader
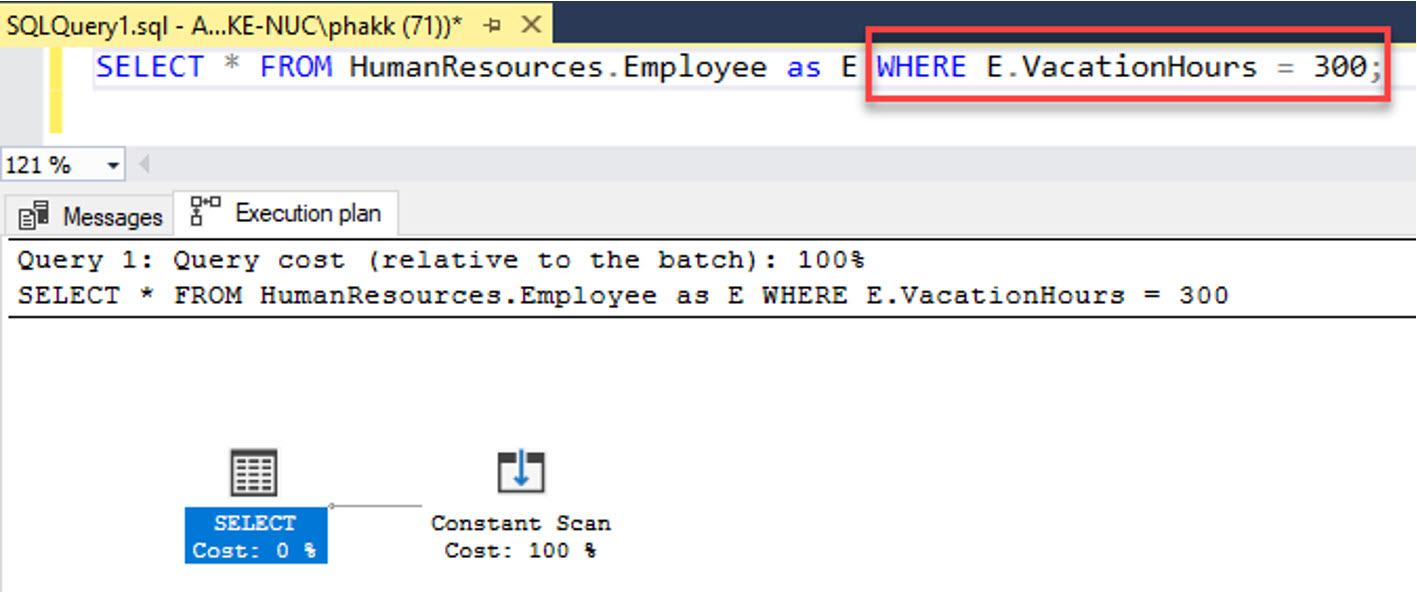
จากรูป เป็นอีกตัวอย่างของขั้นตอน Simplification
จะเห็นว่า Plan ที่ถูกเลือกนำมาใช้ปรากฎตัวดำเนินการ Constant Scan
เพราะ Predicate ที่ใช้ในประโยค WHERE นั้นมีการเปรียบเทียบ VacationHours เกินกว่าที่กำหนดไว้ใน Check Constraint
คือต้องไม่เกิน 240 จึงไม่มีแถวข้อมูลแสดงออกมาตามการกรองนี้ได้
จะเห็นว่า Plan ที่ถูกเลือกนำมาใช้ปรากฎตัวดำเนินการ Constant Scan
เพราะ Predicate ที่ใช้ในประโยค WHERE นั้นมีการเปรียบเทียบ VacationHours เกินกว่าที่กำหนดไว้ใน Check Constraint
คือต้องไม่เกิน 240 จึงไม่มีแถวข้อมูลแสดงออกมาตามการกรองนี้ได้
- ขั้นตอน Trivial Plan Generation
Trivial Plan คือ Plan เล็กๆ ที่มีทางเลือกสร้าง Plan ขึ้นมาแข่งขันได้น้อย สำหรับคิวรี่ประเภทนี้ Query Optimizer จะนำ Plan พื้นๆ มาใช้ ไม่ต้องสร้าง Plan มาแข่งขันกันให้เสียเวลา
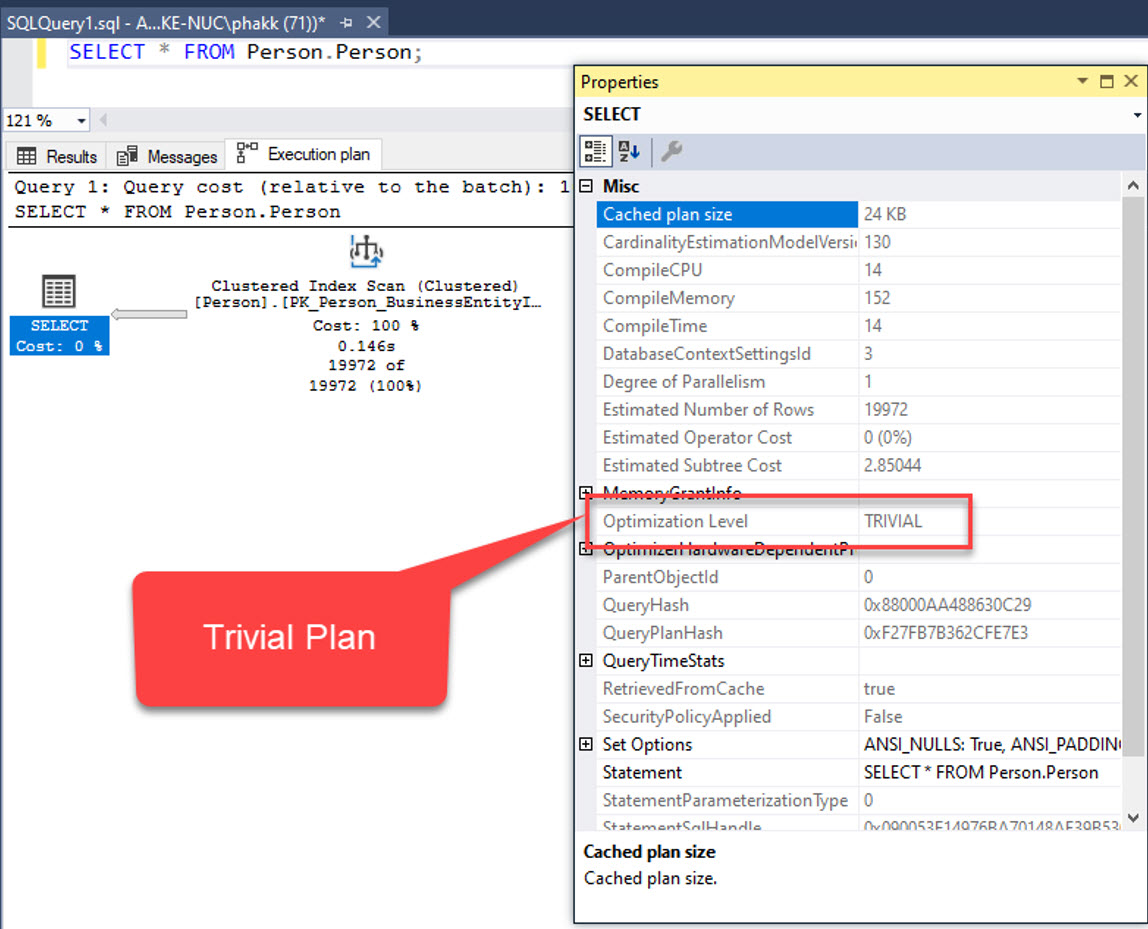
เมื่อบันทึกแล้วจะนำส่งให้ Storage Engine ทำการประมวลผลต่อไป
ขั้นตอนที่ 4 Query Execution
เป็นหน้าที่ของคอมโพเนนต์ใน SQL Server Storage Engine ชื่อว่า Query Executer
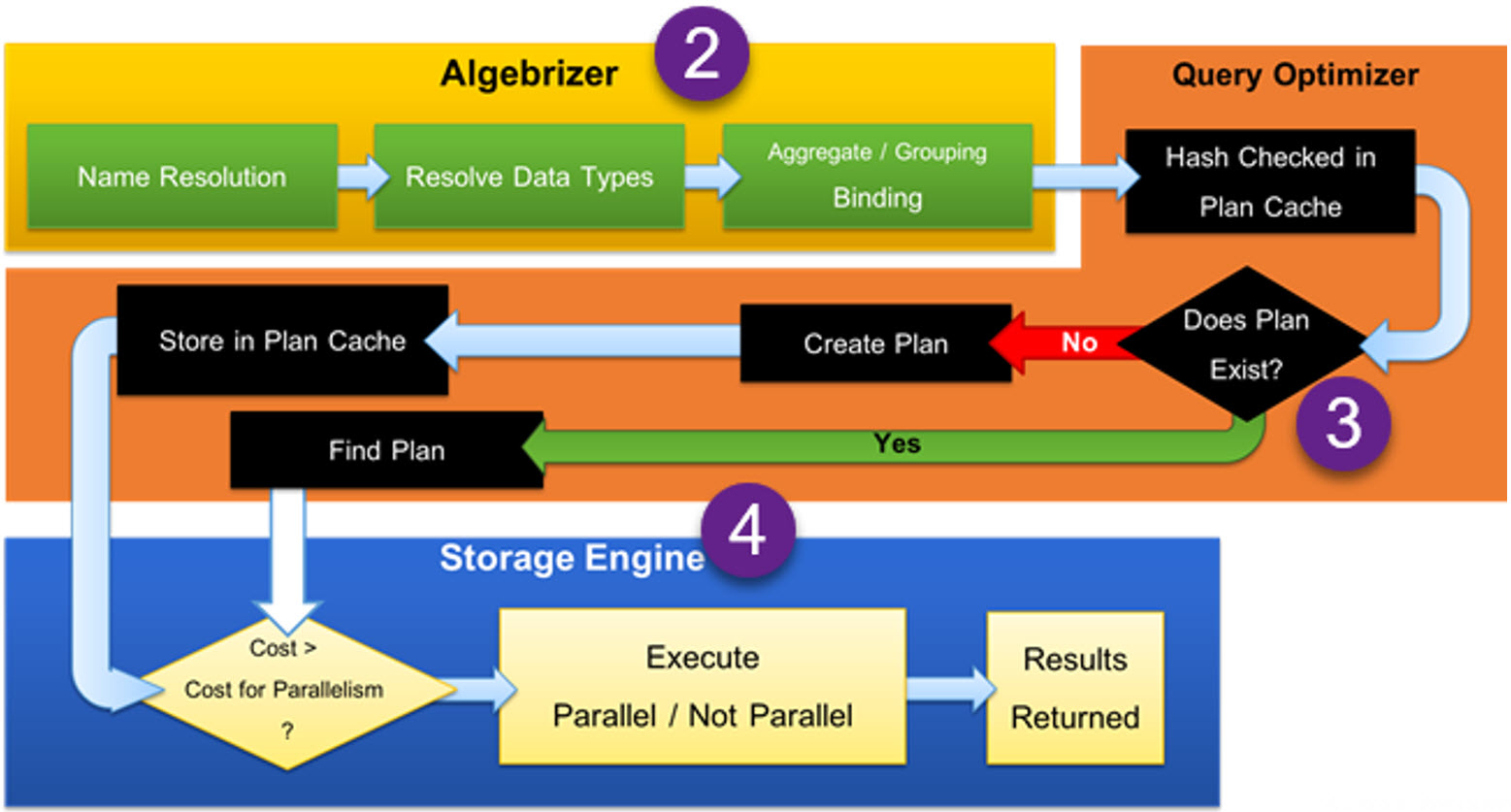
Query Executer จะทำการตรวจสอบว่า Complied Plan ที่ส่งมาจำเป็นต้องประมวลผลแบบ Parallelism หรือไม่
โดยพิจารณาจากค่า Subtree Cost ที่ปรากฎในตัวดำเนิน SELECT ของ Complied Plan ดังแสดง
โดยพิจารณาจากค่า Subtree Cost ที่ปรากฎในตัวดำเนิน SELECT ของ Complied Plan ดังแสดง
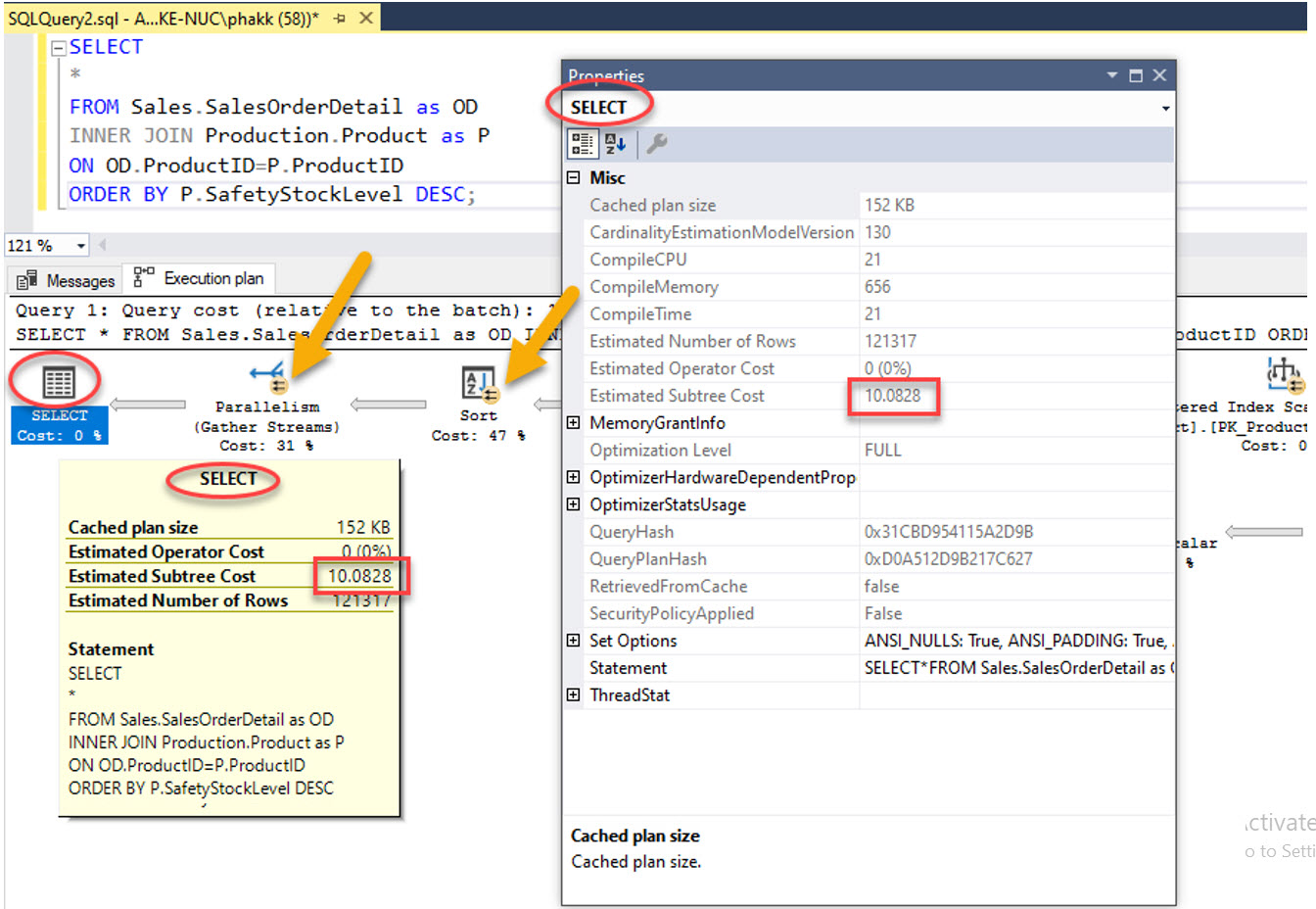
รูป Subtree Cost มีค่าเท่ากับ 10.0828 จะเห็นว่าตัวดำเนินการต่างๆ ประมวลผลแบบ Parallelism (จะปรากฎวงกลมสีเหลืองที่เส้นลูกศรสองเส้นอยู่ภายในแต่ละตัวดำเนินการ)
เกิดจาก Query Executer นำค่า Subtree Cost ไปเปรียบเทียบกับเกณฑ์ ชื่อ Cost Threshold for Parallelism ซึ่งเป็นค่าคอนฟิกระบบ Instance (Server) ดังแสดง
เกิดจาก Query Executer นำค่า Subtree Cost ไปเปรียบเทียบกับเกณฑ์ ชื่อ Cost Threshold for Parallelism ซึ่งเป็นค่าคอนฟิกระบบ Instance (Server) ดังแสดง
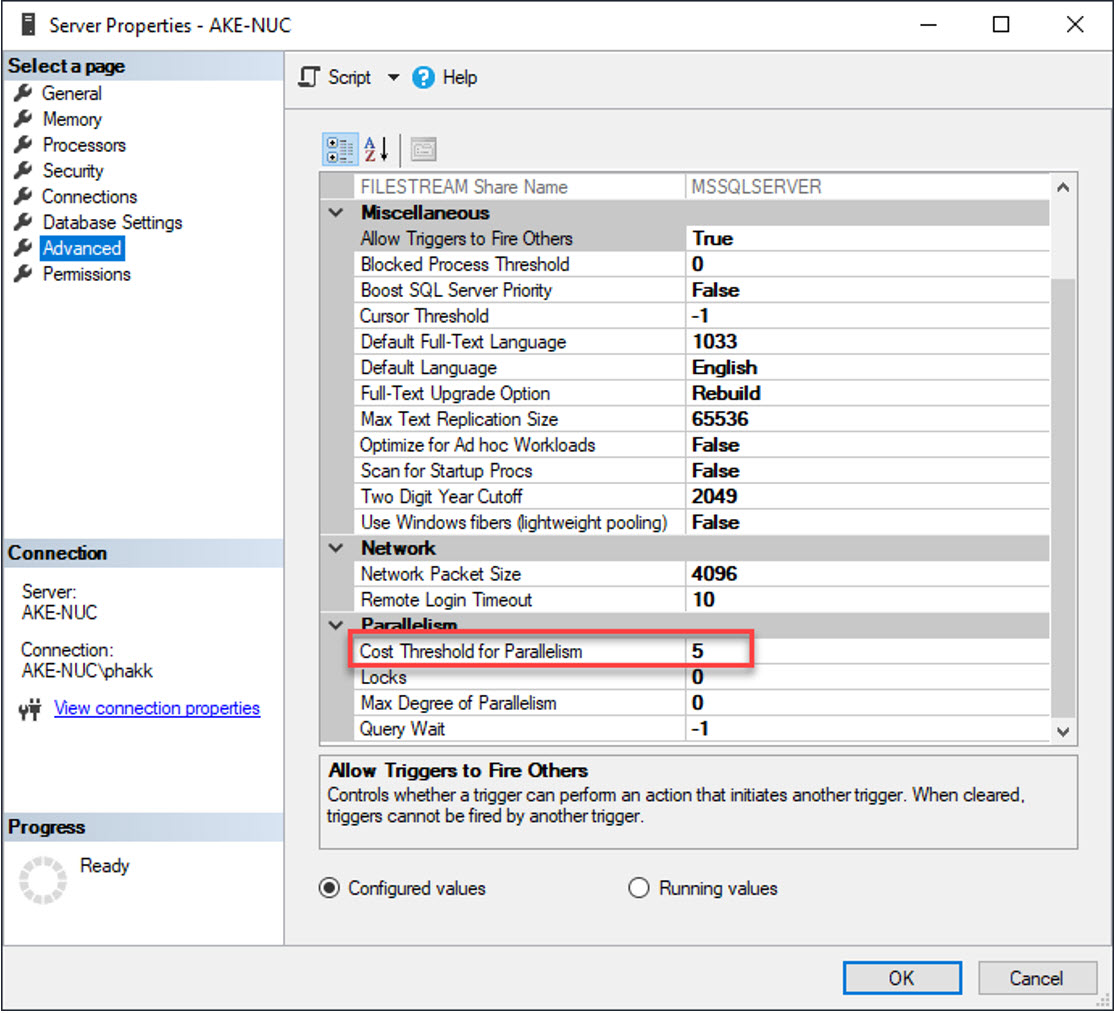
หาก Subtree Cost มีค่ามากกว่าเกณฑ์ จะส่งผลให้เกิดการประมวลผลแบบ Parallelism ขึ้น
เมื่อพิจารณาได้แล้วว่าจะเกิด Parallelism หรือไม่ ก็จะทำการประมวลผลบนจำนวน Core ของ CPU ตามที่ได้ประเมินมา
เมื่อประมวลผลแล้วเสร็จก็จะได้ Resultset กลับออกมา
หมายเหตุ:
Query Executer จะเลือกจำนวน Core ของ CPU ให้ตามความเหมาะสม แต่ไม่เกินเกณฑ์ชื่อ Max Degree of Parallelism (MAXDOP)
ซึ่งเป็นค่าคอนฟิกระบบ Instance (Server) เช่นกัน โดย 0 เป็นค่าตั้งต้นของ MAXDOP
หมายความว่า หนึ่งงาน สามารถรันบน Single core CPU จนถึงสามารถแตกเป็นงานย่อยกระจายประมวลในหลายๆ Core CPU มากสุดเท่าที่ SQL Server มองเห็น
ค่า Cost Threshold for Parallelism และ Max Degree of Parallelism (MAXDOP) ที่เหมาะสม
ผู้อ่านสามารถหาอ่านได้จากบทความก่อนหน้า ที่ผู้เขียนเคยแนะนำไว้ ข่าวดีใน Microsoft SQL Server 2019 จะมีการแนะนำค่า MAXDOP ที่เหมาะสมตาม Best Practice ให้ขณะติดตั้ง
รู้จักกับ Plan Cache กันเพิ่มเติม
ประโยชน์ของ Plan Cache จากขั้นตอน Query Optimization คือใช้เพื่อ Bypass ขั้นตอน Query Optimization ทำให้ลดเวลาการประมวลผลคิวรี่ลง
แต่ Compiled Plan ก็สามารถถูกขับออกจาก Plan Cache ได้หลายกรณีดังนี้
ผู้เขียนคาดว่าผู้ใช้หลายคนมีความกังวลว่าเครื่องที่รัน Microsoft SQL Server อยู่นั้นใช้หน่วยความจำเต็ม 100% และไม่ลดลงเลย กลัวเรื่องเสถียรภาพของ Server
แต่หาก Microsoft SQL Server ยังรันเป็นปกติก็ไม่ควรกังวล
เพราะการปิดเครื่องหรือ Restart Service โดยไม่มีเหตุอันควรนั้นส่งผลเสียมากกว่าผลดี
ที่เห็นชัดมากที่สุดคือ Plan Cache ที่สะสมไว้จะหายไปทั้งหมด
ทุกๆ คิวรี่ และ Stored Procedures ต้องถูกดำเนินการขั้นตอน Query Optimization กันใหม่ ทำให้เสียเวลาและทรัพยากรจำนวนมาก
อีกประเด็นที่สำคัญ คือ ค่าต่างๆ ที่ถูกบันทึกไว้ใน Dynamic Management Objects จะถูก Reset การติดตามประสิทธิภาพการทำงานของ Microsoft SQL Server จะสะดุด
ส่วนการขับไล่ Compiled Plan ออกจาก Plan Cache โดยเจตนานั้น มักทำเพราะ Compiled Plan ของ Stored Procedure เกิดปรากฎการ Parameter Sniffing ขึ้น
จึงต้องแก้ปัญหาด้วยการขับไล่ Compiled Plan ของ Stored Procedure ออกเป็นรายตัว (ไม่แนะนำให้ใช้ CREATE PROCEDURE WITH RECOMPILE แต่ให้ Recompiled เฉพาะเมื่อเกิดปัญหาขึ้น)
Compiled Plan ที่ถูกขับไล่ออกจาก Plan Cache ออกแล้วก็ออกเลย เพราะ ใช้หน่วยความจำในการจัดเก็บ
แต่ใน Microsoft SQL Server 2016 เป็นต้นมา
มีคุณสมบัติ Query Store เพื่อเก็บสำรอง Compiled Plan ที่ถูกขับออกจาก Plan Cache เอาไว้ช่วงระยะเวลาหนึ่งและเป็นการบันทึกลงดิสก์
หากว่า Complied Plan ใหม่ ของคิวรี่ตัวเดียวกัน ทำให้เกิดภาวะถดถอยด้านประสิทธิภาพกว่า Compiled Plan ตัวเก่า เราสามารถนำ Compiled Plan เก่าที่อาจดีกว่ากลับมาบังคับใช้งานได้อีกครั้ง
ถึงแม้จะเป็นแนวคิดที่ดี แต่จะมีผู้ดูแลระบบซักกี่คนที่จะค่อยมาวิเคราะห์การถดถอยของ Compiled Plan ของแต่ละคิวรี่ แล้วมานั่ง Force Plan กัน
ใน Microsoft SQL Server 2017 เป็นต้นมา เราสามารถเปิด Query Store ทิ้งไว้ และตั้งค่าต่อไปนี้
Automatic plan choice correction ทำได้โดย
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
Microsoft SQL Server จะเลือก Force Plan ให้เราโดยอัตโนมัติ น่าจะเป็นทางออกที่เหมาะสมที่สุดของการมีใช้ Query Store
ผู้อ่านสามารถหาอ่านรายละเอียดของ Query Store ได้จากบทความก่อนหน้าของ 9Expert
รู้จักกับ Database Statistics
เราทราบแล้วว่า Database Statistics เป็นส่วนสำคัญที่ใช้ประเมินต้นทุนของกลุ่ม Query Execution Plan
ก่อนนำต้นทุนเหล่านั้นมาประเมินหา Plan ที่เหมาะสมแล้วได้เป็น Compiled Plan ในที่สุด
เมื่อพิจารณาได้แล้วว่าจะเกิด Parallelism หรือไม่ ก็จะทำการประมวลผลบนจำนวน Core ของ CPU ตามที่ได้ประเมินมา
เมื่อประมวลผลแล้วเสร็จก็จะได้ Resultset กลับออกมา
หมายเหตุ:
Query Executer จะเลือกจำนวน Core ของ CPU ให้ตามความเหมาะสม แต่ไม่เกินเกณฑ์ชื่อ Max Degree of Parallelism (MAXDOP)
ซึ่งเป็นค่าคอนฟิกระบบ Instance (Server) เช่นกัน โดย 0 เป็นค่าตั้งต้นของ MAXDOP
หมายความว่า หนึ่งงาน สามารถรันบน Single core CPU จนถึงสามารถแตกเป็นงานย่อยกระจายประมวลในหลายๆ Core CPU มากสุดเท่าที่ SQL Server มองเห็น
ค่า Cost Threshold for Parallelism และ Max Degree of Parallelism (MAXDOP) ที่เหมาะสม
ผู้อ่านสามารถหาอ่านได้จากบทความก่อนหน้า ที่ผู้เขียนเคยแนะนำไว้ ข่าวดีใน Microsoft SQL Server 2019 จะมีการแนะนำค่า MAXDOP ที่เหมาะสมตาม Best Practice ให้ขณะติดตั้ง
รู้จักกับ Plan Cache กันเพิ่มเติม
ประโยชน์ของ Plan Cache จากขั้นตอน Query Optimization คือใช้เพื่อ Bypass ขั้นตอน Query Optimization ทำให้ลดเวลาการประมวลผลคิวรี่ลง
แต่ Compiled Plan ก็สามารถถูกขับออกจาก Plan Cache ได้หลายกรณีดังนี้
- ส่วนของ Plan Cache มีการใช้งานเกินกว่า 50% ของขนาด SQL Server Buffer Pool โดยมีกลไกเลือกขับออกอย่างเป็นระบบ
- Database Statistics ถูกปรับปรุงให้ทันสมัย
- ปิดเครื่องหรือ Restart Service
- ขับออกโดยเจตนา
- รันคำสั่ง DBCC FREEPROCCACHE
- Recompile ในรูปแบบต่างๆ
- CREATE PROCEDURE WITH RECOMPILE
- EXEC sp_recompile
- EXEC WITH RECOMPILE
- ระบุ OPTION (RECOMPILE) ลงในคำสั่ง SELECT
ผู้เขียนคาดว่าผู้ใช้หลายคนมีความกังวลว่าเครื่องที่รัน Microsoft SQL Server อยู่นั้นใช้หน่วยความจำเต็ม 100% และไม่ลดลงเลย กลัวเรื่องเสถียรภาพของ Server
แต่หาก Microsoft SQL Server ยังรันเป็นปกติก็ไม่ควรกังวล
เพราะการปิดเครื่องหรือ Restart Service โดยไม่มีเหตุอันควรนั้นส่งผลเสียมากกว่าผลดี
ที่เห็นชัดมากที่สุดคือ Plan Cache ที่สะสมไว้จะหายไปทั้งหมด
ทุกๆ คิวรี่ และ Stored Procedures ต้องถูกดำเนินการขั้นตอน Query Optimization กันใหม่ ทำให้เสียเวลาและทรัพยากรจำนวนมาก
อีกประเด็นที่สำคัญ คือ ค่าต่างๆ ที่ถูกบันทึกไว้ใน Dynamic Management Objects จะถูก Reset การติดตามประสิทธิภาพการทำงานของ Microsoft SQL Server จะสะดุด
ส่วนการขับไล่ Compiled Plan ออกจาก Plan Cache โดยเจตนานั้น มักทำเพราะ Compiled Plan ของ Stored Procedure เกิดปรากฎการ Parameter Sniffing ขึ้น
จึงต้องแก้ปัญหาด้วยการขับไล่ Compiled Plan ของ Stored Procedure ออกเป็นรายตัว (ไม่แนะนำให้ใช้ CREATE PROCEDURE WITH RECOMPILE แต่ให้ Recompiled เฉพาะเมื่อเกิดปัญหาขึ้น)
Compiled Plan ที่ถูกขับไล่ออกจาก Plan Cache ออกแล้วก็ออกเลย เพราะ ใช้หน่วยความจำในการจัดเก็บ
แต่ใน Microsoft SQL Server 2016 เป็นต้นมา
มีคุณสมบัติ Query Store เพื่อเก็บสำรอง Compiled Plan ที่ถูกขับออกจาก Plan Cache เอาไว้ช่วงระยะเวลาหนึ่งและเป็นการบันทึกลงดิสก์
หากว่า Complied Plan ใหม่ ของคิวรี่ตัวเดียวกัน ทำให้เกิดภาวะถดถอยด้านประสิทธิภาพกว่า Compiled Plan ตัวเก่า เราสามารถนำ Compiled Plan เก่าที่อาจดีกว่ากลับมาบังคับใช้งานได้อีกครั้ง
ถึงแม้จะเป็นแนวคิดที่ดี แต่จะมีผู้ดูแลระบบซักกี่คนที่จะค่อยมาวิเคราะห์การถดถอยของ Compiled Plan ของแต่ละคิวรี่ แล้วมานั่ง Force Plan กัน
ใน Microsoft SQL Server 2017 เป็นต้นมา เราสามารถเปิด Query Store ทิ้งไว้ และตั้งค่าต่อไปนี้
Automatic plan choice correction ทำได้โดย
- เปิด Query Store บนฐานข้อมูลเป้าหมาย
- เปิดคุณสมบัติ Automatic plan choice correction บนฐานข้อมูลเป้าหมาย ดังนี้
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
Microsoft SQL Server จะเลือก Force Plan ให้เราโดยอัตโนมัติ น่าจะเป็นทางออกที่เหมาะสมที่สุดของการมีใช้ Query Store
ผู้อ่านสามารถหาอ่านรายละเอียดของ Query Store ได้จากบทความก่อนหน้าของ 9Expert
รู้จักกับ Database Statistics
เราทราบแล้วว่า Database Statistics เป็นส่วนสำคัญที่ใช้ประเมินต้นทุนของกลุ่ม Query Execution Plan
ก่อนนำต้นทุนเหล่านั้นมาประเมินหา Plan ที่เหมาะสมแล้วได้เป็น Compiled Plan ในที่สุด
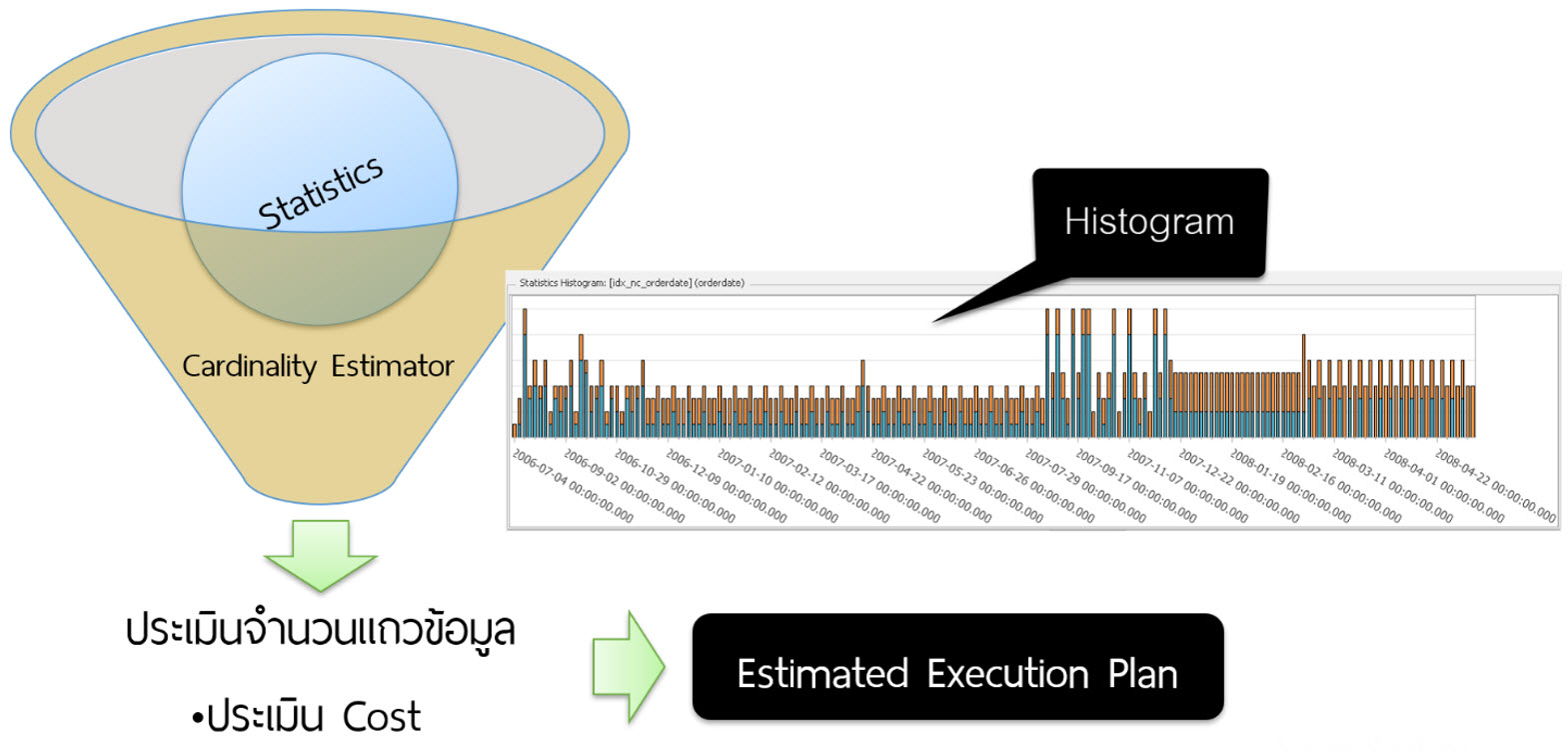
ภายใน Tables จะมีเก็บ Statistics ไว้เพื่อให้คอมโพเนนต์ในกลุ่ม Query Optimization ชื่อ Cardinality Estimator
ทำหน้าที่ประเมินจำนวนแถวข้อมูลที่น่าจะเป็นในแต่ละตัวดำเนินการภายใน Plan
โดย Statistics จะเก็บอยู่ในรูปแบบของฮิสโตแกรมหรือกราฟแจกแจงความถี่
เมื่อประเมินได้จำนวนแถวข้อมูล (จากการคำนวณทางสถิติ) จึงนำไปประเมิน Cost ของ I/O และ CPU ต่อไป
ผู้เขียนจะทดสอบเกี่ยวกับ Statistics ให้เห็นภาพรวมง่ายๆ ผ่านคำสั่งต่อไปนี้
ผู้อ่านสามารถแสดง Estimated Execution Plan (Compiled Plan ที่ยังไม่ Execute) ได้อย่างง่าย
โดยการกด Ctrl-L จะได้ผลลัพธ์ดังแสดง (รายละเอียดเกี่ยวกับ Estimated Execution Plan จะกล่าวถึงในบทความตอนถัดไป)
ทำหน้าที่ประเมินจำนวนแถวข้อมูลที่น่าจะเป็นในแต่ละตัวดำเนินการภายใน Plan
โดย Statistics จะเก็บอยู่ในรูปแบบของฮิสโตแกรมหรือกราฟแจกแจงความถี่
เมื่อประเมินได้จำนวนแถวข้อมูล (จากการคำนวณทางสถิติ) จึงนำไปประเมิน Cost ของ I/O และ CPU ต่อไป
ผู้เขียนจะทดสอบเกี่ยวกับ Statistics ให้เห็นภาพรวมง่ายๆ ผ่านคำสั่งต่อไปนี้
| SELECT SalesOrderID,OrderDate FROM Sales.SalesOrderHeader WHERE Orderdate>='Jan 11,2012' AND orderdate<'Jan 20,2012'; |
ผู้อ่านสามารถแสดง Estimated Execution Plan (Compiled Plan ที่ยังไม่ Execute) ได้อย่างง่าย
โดยการกด Ctrl-L จะได้ผลลัพธ์ดังแสดง (รายละเอียดเกี่ยวกับ Estimated Execution Plan จะกล่าวถึงในบทความตอนถัดไป)
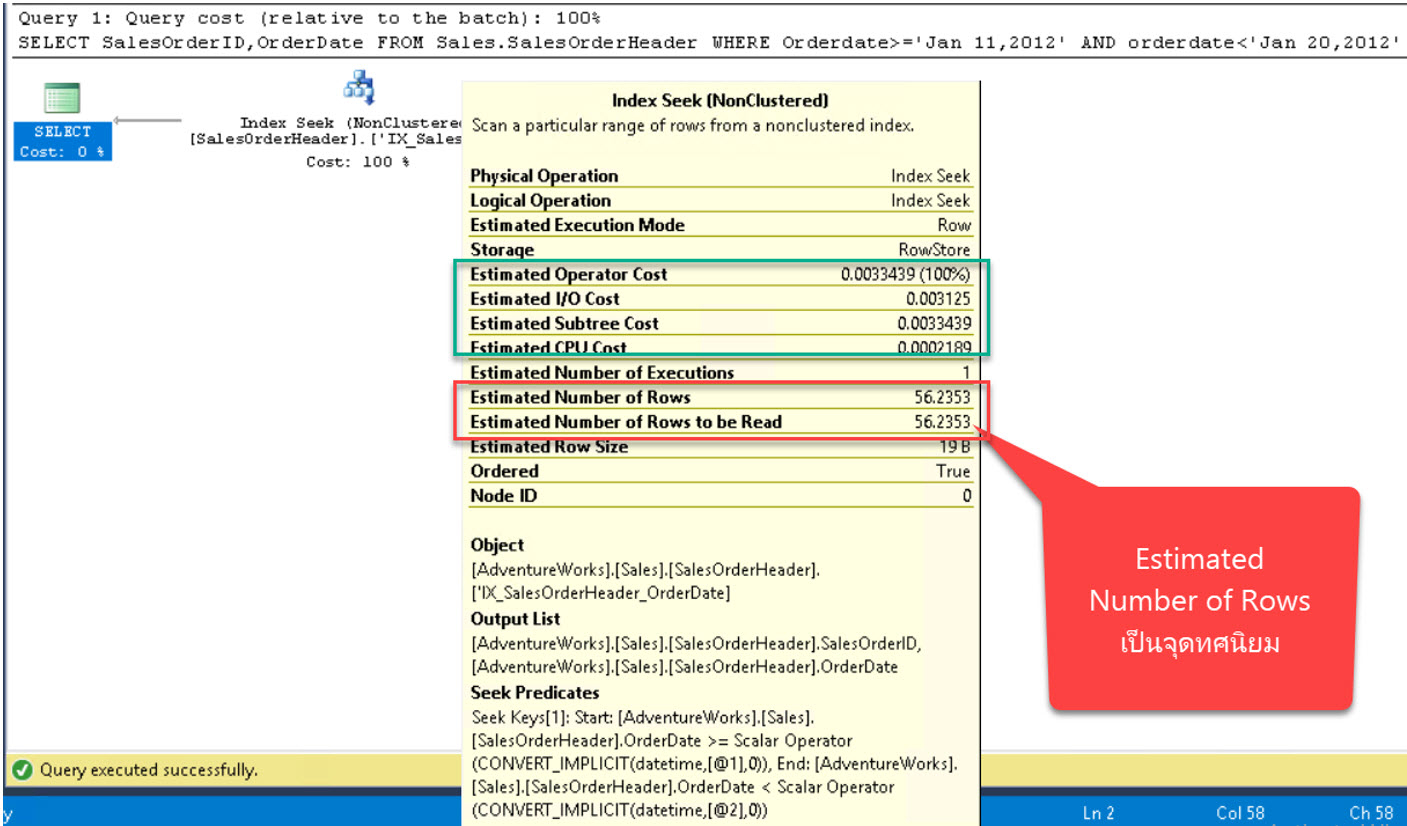
พบว่า Cardinality Estimator ประเมินจำนวนแถวข้อมูลได้ออกมาเป็นจำนวน 56.2353 แถว
สังเกตว่าเป็นค่าติดจุดทศนิยม จำนวนแถวข้อมูลต้องเป็นค่าคงที่ จึงยืนยันได้ว่า Cardinality Estimator มีกลไกคำนวณจาก
ผลลัพธ์ที่ได้ดังแสดง
สังเกตว่าเป็นค่าติดจุดทศนิยม จำนวนแถวข้อมูลต้องเป็นค่าคงที่ จึงยืนยันได้ว่า Cardinality Estimator มีกลไกคำนวณจาก
- การคำนวณทางสถิติ
- เดาค่าตามกฎที่ตั้งไว้
| DBCC SHOW_STATISTICS('Sales.SalesOrderHeader','IX_SalesOrderHeader_OrderDate') WITH HISTOGRAM; |
ผลลัพธ์ที่ได้ดังแสดง
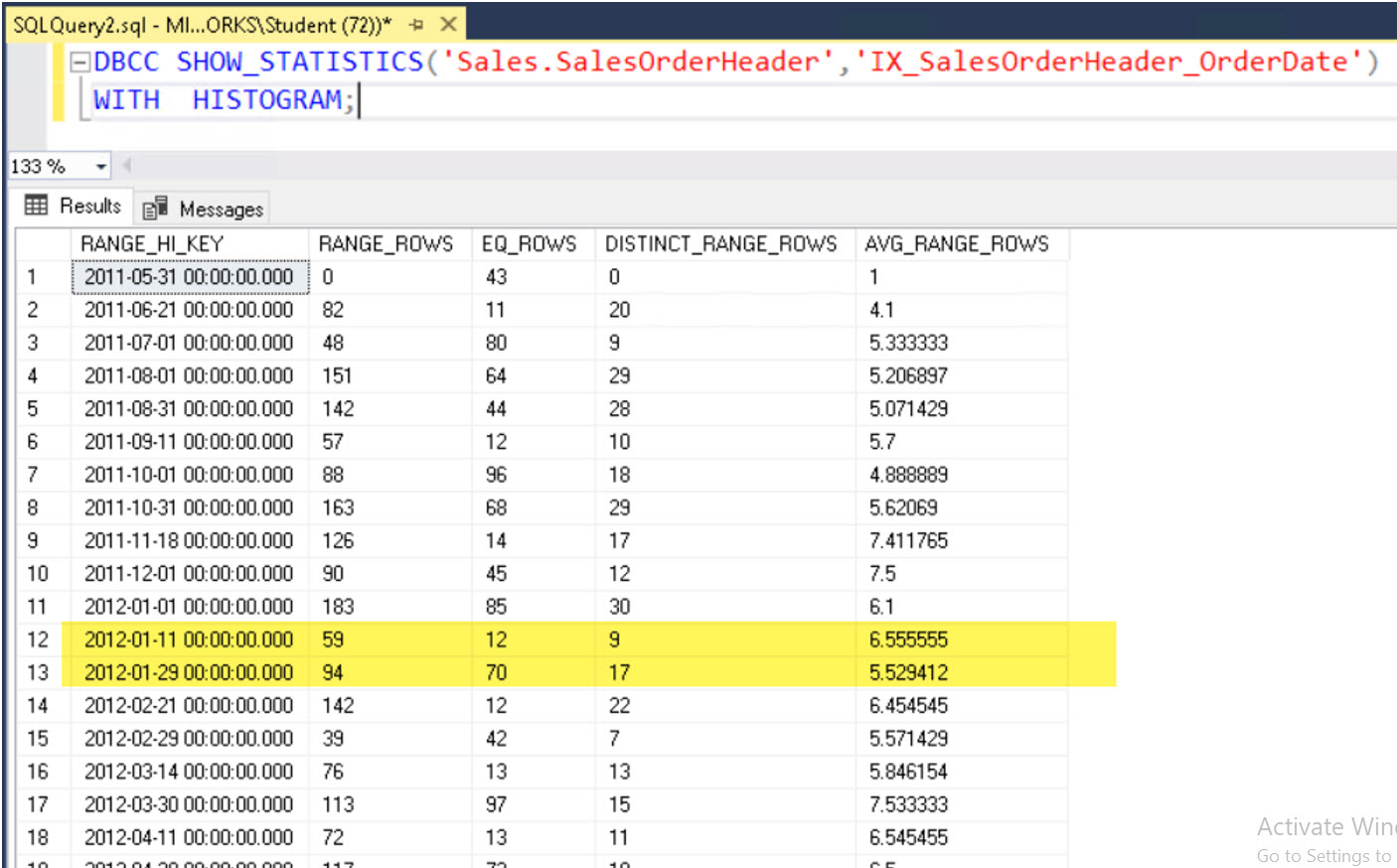
จะเห็นว่าเงื่อนไขหลังประโยค WHERE ตกในช่วงที่ผู้เขียนไฮไลท์เอาไว้
คือ ระหว่างวันที่ Jan 1,2012 จนถึง Jan 20, 2012 จำนวนแถวข้อมูลในวันที่ Jan 1,2012 จะมี 12 แถวข้อมูล ดูได้จากคอลัมน์ EQ_ROWS
แต่สำหรับวันที่เหลือไปจนถึงวันที่ Jan 20, 2012 คำนวณได้จากการนำวันที่เหลือไปหา Factor ของหนึ่งหน่วยเวลาภายในช่วงวันดังกล่าว
ได้ค่า Factor ออกมาเท่ากับ 0.5 นำไปคำนวณต่อในสูตรต่อไปนี้
Factor = 0.5
AVG_RANGE_ROWS ของฮิสโตแกรมแท่งสุดท้าย = 5.529412
DISTINCT_RANGE_ROWS ของฮิสโตแกรมแท่งสุดท้าย = 17
Estimated Number of Rows = 5.529412 x 0.5 x 16 = 44.235296
จากนั้นนำไปบวกกับจำนวนแถวของวันที่ Jan 1,2012 จำนวน 12 แถว รวมเป็น 44.235296 + 12 = 56.235296
จะเห็นว่าตรงกันกับที่ Cardinality Estimator คำนวณได้มา
จากนั้นนำจำนวน แถวที่ได้ไปคาดคะเน IO Cost และ CPU Cost
จนได้ออกมาเป็น Subtree Cost เพื่อได้ต้นทุนของแต่ละ Plan
สรุป
ความรู้เหล่านี้ มีความสำคัญต่อการแปลความหมายของ Execution Plan
ในตอนต่อไปผู้เขียนจะเล่าถึงประเภทของ Display Execution Plan และแนวทางการแปลความหมายจาก Display Execution Plan
ผลกระทบต่อประสิทธิภาพที่พบบ่อยแล้วปรากฎใน Display Execution Plan รวมถึงแนวทางการแก้ไข
คือ ระหว่างวันที่ Jan 1,2012 จนถึง Jan 20, 2012 จำนวนแถวข้อมูลในวันที่ Jan 1,2012 จะมี 12 แถวข้อมูล ดูได้จากคอลัมน์ EQ_ROWS
แต่สำหรับวันที่เหลือไปจนถึงวันที่ Jan 20, 2012 คำนวณได้จากการนำวันที่เหลือไปหา Factor ของหนึ่งหน่วยเวลาภายในช่วงวันดังกล่าว
| DECLARE @TargetDate datetime = 'Jan 20, 2012 00:00:00' --วันสุดท้ายที่ระบุใน WHERE , @Low datetime = 'Jan 11, 2012 00:00:00' --ช่วงข้อมูลที่มีใน Histogram , @High datetime = 'Jan 29, 2012 00:00:00'; --ช่วงข้อมูลที่มีใน Histogram DECLARE @QTarget float = DATEDIFF(MILLISECOND, @Low, @TargetDate) , @SRange float = DATEDIFF(MILLISECOND, @Low, @High) SELECT @QTarget/@SRange as Factor; |
ได้ค่า Factor ออกมาเท่ากับ 0.5 นำไปคำนวณต่อในสูตรต่อไปนี้
| Estimated Number of Rows = AVG_RANGE_ROWS * Factor * (DISTINCT_RANGE_ROWS - 1)) |
Factor = 0.5
AVG_RANGE_ROWS ของฮิสโตแกรมแท่งสุดท้าย = 5.529412
DISTINCT_RANGE_ROWS ของฮิสโตแกรมแท่งสุดท้าย = 17
Estimated Number of Rows = 5.529412 x 0.5 x 16 = 44.235296
จากนั้นนำไปบวกกับจำนวนแถวของวันที่ Jan 1,2012 จำนวน 12 แถว รวมเป็น 44.235296 + 12 = 56.235296
จะเห็นว่าตรงกันกับที่ Cardinality Estimator คำนวณได้มา
จากนั้นนำจำนวน แถวที่ได้ไปคาดคะเน IO Cost และ CPU Cost
จนได้ออกมาเป็น Subtree Cost เพื่อได้ต้นทุนของแต่ละ Plan
สรุป
ความรู้เหล่านี้ มีความสำคัญต่อการแปลความหมายของ Execution Plan
ในตอนต่อไปผู้เขียนจะเล่าถึงประเภทของ Display Execution Plan และแนวทางการแปลความหมายจาก Display Execution Plan
ผลกระทบต่อประสิทธิภาพที่พบบ่อยแล้วปรากฎใน Display Execution Plan รวมถึงแนวทางการแก้ไข
บทความที่เกี่ยวข้อง
